Contraste conjunto de aprendizaje
Contraste conjunto de aprendizaje es una forma de aprendizaje de reglas de asociación que busca identificar diferencias significativas entre grupos separados por técnicas de ingeniería inversa los predictores claves que identifican a cada grupo en particular. Por ejemplo, dado un conjunto de atributos para un grupo de estudiantes (marcada por el tipo de grado), un aprendiz de ajuste contraste identificaría la en contraste características entre estudiantes que buscan licenciaturas y aquellos que trabajan hacia el doctorado.
Contenido
- 1 Resumen
- 1.1 Ejemplo: Supermercado compras
- 2 Aprendizaje de tratamiento
- 2.1 Ejemplo: Boston vivienda datos
- 3 Algoritmos
- 3.1 ESTUCO
- 3.2 TAR3
- 4 Referencias
Resumen
Una práctica común en minería de datos es clasificar, a mirar los atributos de un objeto o una situación y hacer una suposición en qué categoría del elemento observado pertenece a. Como nuevas pruebas se examinaron (típicamente por la alimentación de un entrenamiento conjunto para un aprendizaje algoritmo), estas conjeturas son refined y mejorado. Contraste establece aprendizaje funciona en la dirección opuesta. Mientras que classifiers leer una colección de datos y recopilar información que se utiliza para colocar nuevos datos en una serie de categorías discretas, contraste conjunto de aprendizaje toma la categoría que un elemento pertenece a e intenta la evidencia estadística que identifica un elemento como un miembro de una clase de ingeniería inversa. Es decir, contraste define a aprendiendo reglas buscan asociar los valores de atributo con cambios en la distribución de la clase.[1] Buscan identificar los predictores claves que contrastan con una clasificación de otro.
Por ejemplo, un ingeniero aeroespacial puede registrar datos sobre los lanzamientos de prueba de un nuevo cohete. Las medidas se tomarían en intervalos regulares a lo largo de la puesta en marcha, teniendo en cuenta factores tales como la trayectoria del cohete, operando las temperaturas, presiones externas y así sucesivamente. Si el lanzamiento del cohete falla después de una serie de pruebas exitosas, el ingeniero puede utilizar contraste conjunto aprendiendo a distinguir entre las pruebas exitosas y fallidas. Un aprendiz ajuste contraste producen un conjunto de asociación reglas que, cuando se aplica, se indicará los principales predictores de cada pruebas fallidas contra los exitosos (la temperatura era muy alta, la presión del viento era demasiado alto, etc.).
Contraste conjunto de aprendizaje es una forma de aprendizaje de reglas de asociación.[2] Estudiantes de la regla de asociación típicamente ofrecen normas UNE atributos que ocurren comúnmente juntos en un sistema de entrenamiento (por ejemplo, personas que están inscritos en programas de cuatro años y lleva una carga de curso completo tienden a vivir también cerca del campus). En lugar de encontrar reglas que describen la situación actual, contraste establece a los estudiantes buscan reglas difieren significativamente en su distribución entre los grupos (y por lo tanto, pueden utilizarse como predictores de esos grupos).[3] Por ejemplo, un aprendiz ajuste contraste podría preguntar, "¿Qué son los identificadores de clave de una persona con una licenciatura o una persona con un doctorado y cómo la gente con doctorados y licenciaturas difieren?"
Estándar clasificador algoritmos, tales como C4.5, no tienen el concepto de la importancia de la clase (es decir, no saben si una clase es "bueno" o "malo"). Tal aprendizaje no puede sesgar o filtrar sus predicciones hacia ciertas clases deseadas. Como el objetivo del contraste establecido es descubrir las diferencias significativas entre los grupos de aprendizaje, es útil poder atacar las reglas aprendidas hacia algunas clasificaciones. Varios contraste establece los estudiantes, tales como MINWAL[4] o la familia de algoritmos de alquitrán,[5][6][7] asignar pesos a cada clase para enfocar las teorías aprendidas hacia los resultados que son de interés para un público determinado. Así, puede ser sin embargo contraste conjunto de aprendizaje de como una forma de aprendizaje clase ponderado.[8]
Ejemplo: Supermercado compras
Las diferencias entre la clasificación estándar, Asociación regla aprendizaje y contraste conjunto de aprendizaje pueden ser ilustradas con una metáfora simple supermercado. En el siguiente pequeño dataset, cada fila es una transacción de supermercado y cada "1" indica que el producto fue comprado (un "0" indica que el elemento no se compró):
| Hamburguesa | Patatas | Foie Gras | Cebollas | Champagne | Propósito de compras |
|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 0 | Parrillada |
| 1 | 1 | 0 | 1 | 0 | Parrillada |
| 0 | 0 | 1 | 0 | 1 | Aniversario |
| 1 | 1 | 0 | 1 | 0 | Parrillada |
| 1 | 1 | 0 | 0 | 1 | Fiesta de la fraternidad |
Dados estos datos,
- Aprendizaje de reglas de asociación puede descubrir que los clientes que compran las cebollas y papas juntos están probables que también comprar carne de la hamburguesa.
- Clasificación puede descubrir que los clientes que compraron carnes de hamburguesa, papas y cebollas estaban comprando artículos para una barbacoa.
- Contraste conjunto de aprendizaje puede descubrir que la principal diferencia entre los clientes de compras para una parrillada y las compras para una cena de aniversario son que los clientes adquirir artículos para una barbacoa comprar cebollas, patatas y carne de la hamburguesa (y No compre foie gras o champán).
Aprendizaje de tratamiento
Aprendizaje de tratamiento es una forma de aprendizaje conjunto de contraste ponderado toma una sola deseable Grupo y se contrasta contra el restante indeseables grupos (el nivel de conveniencia está representado por las clases medias ponderadas).[5] El "tratamiento" resultante sugiere un conjunto de reglas que, cuando aplica, conducirá al resultado deseado.
Aprendizaje tratamiento difiere de contraste estándar conjunto de aprendizaje a través de las siguientes restricciones:
- En lugar de buscar las diferencias entre todos los grupos, aprendizaje tratamiento especifica un grupo en particular para centrarse en, aplica un peso a esta agrupación deseada y los grupos restantes de los terrones en una categoría "no deseada".
- Tratamiento aprendizaje tiene un foco declarado en teorías mínimas. En la práctica, están limitadas a un máximo de cuatro contraints tratamiento (es decir, en lugar de indicar todas las razones que un cohete difiere de un monopatín, un aprendiz de tratamiento indicará uno a cuatro importantes diferencias que predicen para cohetes a un alto nivel de significación estadística).
Este enfoque en la simplicidad es una meta importante para los estudiantes de tratamiento. Tratamiento de aprendizaje busca la más pequeño el cambio que tiene el mayor impacto en la distribución de la clase.[8]
Conceptualmente, los educandos tratamiento exploran todos los subconjuntos posibles de la gama de valores para todos los atributos. Una búsqueda tan a menudo es inviable en la práctica, así tratamiento aprendiendo a menudo se centra en cambio en poda rápidamente y, ignorando el atributo varía cuando se aplica, conducen a una distribución de clase donde la clase deseada está en la minoría.[7]
Ejemplo: Boston vivienda datos
El siguiente ejemplo muestra la salida del aprendiz de tratamiento TAR3 en un conjunto de datos de la ciudad de la vivienda Boston (no trivial dataset público con más de 500 ejemplos). En este conjunto de datos, se recoge una serie de factores para cada casa y cada casa se clasifica según su calidad (baja, media baja, media alta y alta). El la deseada clase se establece a "alto", y el resto de clases se agrupan como indeseables.
La salida del aprendiz de tratamiento es como sigue:
Distribución de clase base: baja: 29% medlow: 29% medhigh: 21% alta: 21%
Tratamiento sugerido: [PTRATIO=[12.6..16), RM=[6.7..9.78)]
Nueva distribución de la clase: bajo: 0% medlow: 0% medhigh: 3% alto: 97%
No hay tratamientos aplicados (reglas), la clase deseada representa sólo el 21% de la distribución de la clase. Sin embargo, si filtramos el conjunto de datos para las casas con 6.7 a 9,78 habitaciones y una proporción de padres y maestros barrio de 12,6 a 16, luego el 97% de los ejemplos restantes caen en la clase deseada (casas de alta calidad).
Algoritmos
Hay una serie de algoritmos que realizan contraste conjunto de aprendizaje. Las subsecciones siguientes describen dos ejemplos.
ESTUCO
El contraste de estuco conjunto aprendiz[1][3] trata la tarea de aprendizaje de contraste se establece como un árbol de búsqueda problema donde el nodo raíz del árbol es un contraste vacío el set. Los niños se agregan mediante la especialización el conjunto con elementos adicionales que eligió a través de un ordenamiento canónico de atributos (para evitar visitar los nodos mismos dos veces). Los niños se forman añadiendo términos que siguen todos los términos existentes en un orden determinado. El árbol formado es buscado en forma amplitud-primero. Teniendo en cuenta los nodos en cada nivel, se analiza el conjunto de datos y el apoyo se cuenta para cada grupo. Cada nodo entonces es examinada para determinar si es importante y grande, si se deben ser podado, y si deben generar nuevos niños. Después de todos los conjuntos de contraste significativo se encuentran, un postprocesador selecciona un subconjunto para mostrar al usuario - la orden de baja, más simples se muestran los resultados primeros, seguido por los resultados de orden superiores que son "sorprendentes y significativamente diferentes.[3]"
El cálculo de la ayuda proviene de probar una hipótesis nula que el apoyo conjunto de contraste es igual en todos los grupos (es decir, que contraste definido apoyo es independiente de la pertenencia a un grupo). La cuenta de apoyo para cada grupo es establece un valor de frecuencia que puede ser analizado en una tabla de contingencia donde cada fila representa el valor de verdad del contraste y cada variable columna indica la frecuencia de pertenencia de grupo. Si hay una diferencia en las proporciones entre el contraste las frecuencias y los de la hipótesis nula, el algoritmo debe entonces determinar si las diferencias en las proporciones que representan una relación entre variables o si se puede atribuir a causas aleatorias. Esto puede ser determinado a través de un prueba de Chi cuadrado comparando la frecuencia observada cuenta a la cuenta prevista.
Se podan los nodos del árbol cuando todas las especializaciones del nodo nunca pueden llevar a un conjunto importante y gran contraste. La decisión de podar se basa en:
- El tamaño mínimo de desviación: la diferencia máxima entre el apoyo de cualquier arresto de dos grupos ser mayor que un umbral especificado por el usuario.
- Espera las frecuencias celulares: las frecuencias esperadas de la célula de una tabla de contingencia sólo pueden disminuir como el conjunto de contraste es especializado. Cuando estas frecuencias son demasiado pequeñas, la validez de la prueba de Chi-cuadrado es violada.
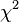 límites: un límite superior se mantiene en la distribución de una estadística calculada cuando la hipótesis nula es verdadera. Los nodos son podados cuando ya no es posible cumplir con este atajo.
límites: un límite superior se mantiene en la distribución de una estadística calculada cuando la hipótesis nula es verdadera. Los nodos son podados cuando ya no es posible cumplir con este atajo.
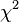 límites: un límite superior se mantiene en la distribución de una estadística calculada cuando la hipótesis nula es verdadera. Los nodos son podados cuando ya no es posible cumplir con este atajo.
límites: un límite superior se mantiene en la distribución de una estadística calculada cuando la hipótesis nula es verdadera. Los nodos son podados cuando ya no es posible cumplir con este atajo.TAR3
El TAR3[6][9] aprendizaje conjunto ponderado contraste se basa en dos conceptos fundamentales - la Levante y apoyo de un conjunto de reglas.
La elevación de un conjunto de reglas es el cambio que pone a una decisión de un conjunto de ejemplos después de imponer esa decisión (por ejemplo, cómo la distribución de clase cambios en respuesta a la imposición de una regla). TAR3 busca el más pequeño conjunto de reglas que induce los cambios más grandes en la suma de los pesos que se adjunta a cada clase multiplicada por la frecuencia en que se produce cada clase. El ascensor se calcula dividiendo la puntuación del conjunto en el que el conjunto de reglas se impone por el marcador de la línea de fondo (es decir, no hay reglas se aplican). Tenga en cuenta que invirtiendo la elevación anotando la función, el aprendiz de TAR3 también puede seleccionar para las clases restantes y rechazar la clase de destino.
Es problemático que depender de la elevación de un solo conjunto de reglas. Ruido de información incorrecta o engañosa, si correlacionado con su defecto ejemplos, puede resultar en un conjunto de reglas overfitted. Un modelo tan overfitted puede tener una puntuación de elevación grande, pero no exactamente hace reflexionar las condiciones prevalecientes en el conjunto de datos. Para evitar el desbordamiento, TAR3 utiliza un umbral de apoyo y rechaza todas las reglas que se encuentran en el lado equivocado de este umbral. Dada una clase de destino, el umbral de apoyo es un valor suministrado por el usuario (generalmente 0,2) que es comparado con el cociente de la frecuencia de la clase de destino cuando el conjunto de reglas se ha aplicado a la frecuencia de esa clase en la base de datos global. TAR3 rechaza todos los conjuntos de reglas con soporte inferior a este umbral.
Por que requiere una gran capacidad de elevación y un soporte de alto valor, TAR3 no sólo devuelve los conjuntos de reglas ideales, sino que también favorece a pequeños conjuntos de reglas. Las normas menos adoptadas, la evidencia más que existirá apoyo a esas reglas.
El algoritmo TAR3 construye solamente sistemas de reglas de rangos de valor de atributo con un alto valor heurístico. El algoritmo determina que se extiende a usar primero determinar la puntuación de elevación de rangos de los valores de cada atributo. Estas puntuaciones individuales son ordenadas y convertidas en una distribución de probabilidad acumulativa. TAR3 al azar selecciona los valores de esta distribución, lo que significa que las gamas baja puntuación son pocas probabilidades de ser seleccionado. Para construir a un candidato conjunto de reglas, varias gamas son seleccionadas y combinadas. Estos conjuntos de reglas candidato entonces anotó y ordenados. Si no se ve ninguna mejoría después de un número de rondas definidas por el usuario, el algoritmo termina y devuelve los mayor puntaje los conjuntos de reglas.
Referencias
- ^ a b Bahía de Stephen y Michael Pazzani (2001). "Detectar las diferencias entre Grupo: conjuntos de contraste de minas". Minería de datos y descubrimiento de conocimiento 5 (3): 213 – 246.
- ^ GI Webb y S. Butler y Newlands D. (2003). "En la detección de diferencias entre los grupos". KDD'03 Proceedings de la novena Conferencia Internacional ACM SIGKDD sobre descubrimiento de conocimiento y minería de datos.
- ^ a b c Bahía de Stephen y Michael Pazzani (1999). "Detección de cambio en los datos categóricos: minería conjuntos de contraste". KDD 99 Proceedings of la Quinta Conferencia Internacional ACM SIGKDD sobre descubrimiento de conocimiento y minería de datos.
- ^ C.H. Cai, A.W.C. Fu, C.H. Cheng y W.W. Kwong (1998). "Las reglas de asociación con elementos cargados de minas". Actas del Simposio de aplicaciones (IDEAS 98) y base de datos internacional de ingeniería.
- ^ a b Hu Y. (2003). Aprendizaje de tratamiento: implementación y aplicación (Tesis de maestría). Departamento de ingeniería eléctrica, Universidad de Columbia Británica.
- ^ a b K. Gundy-Burlet, J. Schumann, Barrett T. y T. Menzies (2007). "Análisis paramétrico de ANTARES reingreso orientación algoritmos usando análisis de datos y generación de pruebas avanzadas". En IX Simposio Internacional sobre inteligencia artificial, robótica y automatización en el espacio.
- ^ a b Gregory Gay, Tim Menzies, Misty Davies y Karen Gundy-Burlet (2010). "Encontrar automáticamente las Variables de Control para un comportamiento complejo del sistema". Ingeniería de Software automatizado 17 (4).
- ^ a b T. Menzies y Y. Hu (2003). "Minería de datos para gente muy ocupada". IEEE Computer 36 (11): 22 – 29. Doi:10.1109/MC.2003.1244531.
- ^ J. Schumann, K. Gundy-Burlet, C. Pasareanu, T. Menzies y A. Barrett (2009). "Software V & V apoyo Análisis paramétrico de sistemas de simulación de software grandes". Actas de la Conferencia aeroespacial 2009 IEEE.