HyperLogLog
|
|
|
HyperLogLog es un algoritmo para el problema Conde-distintas, aproximar el número de elementos distintos en una MultiSet[1] (el Cardinalidad).
Cálculo de la Exacto Cardinalidad de un multiset requiere una cantidad de memoria proporcional a la cardinalidad, que no es práctica para conjuntos de datos muy grandes. Estimadores de cardinalidad probabilísticos, como el algoritmo HyperLogLog, utilizan significativamente menos memoria que esto, a costa de obtener sólo una aproximación de la cardinalidad. El algoritmo de HyperLogLog es capaz de estimar la cardinalities de  con una precisión típica de 2%, utilizando 1,5 kB de memoria.[1] HyperLogLog es una extensión del algoritmo LogLog anterior.[2]
con una precisión típica de 2%, utilizando 1,5 kB de memoria.[1] HyperLogLog es una extensión del algoritmo LogLog anterior.[2]
Algoritmo
La base del algoritmo de HyperLogLog es la observación que la cardinalidad de un conjunto múltiple de números aleatorios uniformemente distribuidos puede estimarse calculando el máximo número de ceros en la representación binaria de cada número en el conjunto. Si observa el máximo número de ceros es  , es una estimación del número de elementos distintos del conjunto
, es una estimación del número de elementos distintos del conjunto 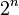 .[1]
.[1]
En el algoritmo de HyperLogLog, un función hash se aplica a cada elemento en el multiset original, para obtener un conjunto múltiple de números aleatorios uniformemente distribuidos con la misma cardinalidad como la original multiset. La cardinalidad de este conjunto distribuidas al azar puede estimarse entonces utilizando el algoritmo de arriba.
La simple estimación de cardinalidad obtenido utilizando el algoritmo de arriba tiene la desventaja de un grande varianza. En el algoritmo de HyperLogLog, la varianza es minimizada dividiendo el multiset en numerosos subgrupos, calcular el máximo el número de ceros en los números en cada uno de estos subconjuntos y utilizando un media armónica para combinar estas estimaciones para cada subconjunto en una estimación de la cardinalidad del conjunto.
Empresas que utilizan Hyperloglog
- mParticle [3]
- El almacén de datos de clave y valor Redis tiene una implementación de HyperLogLog.[4]
Referencias
- ^ a b c Flajolet, P.; Fusy, E.; Gandouet, O.; Meunier, f el. (2007). "AOFA ' 07: actas de la Conferencia Internacional de 2007 en el análisis de algoritmos".
|Chapter =(ignoradoAyuda) - ^ Durand, M.; Flajolet, P. (2003). G. Di Battista y U. Zwick, ed. "Lecture Notes in Computer Science". Simposio Anual Europeo sobre algoritmos (ESA03) 2832. Springer. págs. 605 – 617.
|Chapter =(ignoradoAyuda) - ^ https://blog.mparticle.com/a-must-know-for-Data-Scientists-hyperloglog-Algorithm/
- ^ Nueva estructura de datos Redis: la HyperLogLog
- "Las estructuras de datos probabilísticos de analítica Web y minería de datos | Altamente escalable Blog". highlyscalable.wordpress.com. 19 / 04 / 2014.
- "com.twitter.algebird.HyperLogLogMonoid". Twitter.github.Io. 19 / 04 / 2014.
- "twitter/summingbird · GitHub". github.com. 19 / 04 / 2014.
- "HyperLogLog en la práctica: Ingeniería algorítmica de un algoritmo de estimación de cardinalidad State of The Art". Research.google.com. 19 / 04 / 2014.
- https://pnwscala.org/Talks/SamRitchie-PNWScalaTalk.pdf