PageRank
|
|
Este artículo es anticuado. (Febrero de 2014) |
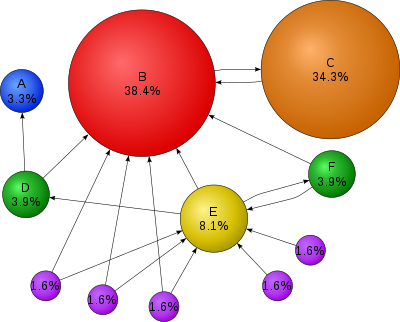
PageRank es un algoritmo utilizado por Búsqueda de Google a fila sitios web en los resultados de su motor de búsqueda. PageRank fue nombrado después de Larry Page,[1] uno de los fundadores de Google. PageRank es una manera de medir la importancia de las páginas Web. Según Google:
PageRank trabaja contando el número y calidad de enlaces de una página para determinar una estimación aproximada de lo importante que es el sitio Web. La suposición subyacente es que sitios web más importante es propensos a recibir mas links de otros sitios Web.[2]
No es el único algoritmo utilizado por Google para ordenar los resultados del motor de búsqueda, pero es el primer algoritmo que fue utilizado por la compañía, y es el más conocido.[3][4]
Contenido
- 1 Descripción
- 2 Historia
- 3 Algoritmo
- 3.1 Algoritmo simplificado
- 3.2 Factor de amortiguación
- 3.3 Cómputo
- 3.3.1 Iterativo
- 3.3.2 Algebraica
- 3.3.3 Método de la energía
- 3.3.4 Eficiencia
- 4 Variaciones
- 4.1 PageRank de un gráfico sin señas
- 4.2 Algoritmo distribuido para el cómputo de PageRank
- 4.3 Google Toolbar
- 4.4 SERP Rank
- 4.5 Directorio de Google PageRank
- 4.6 PageRank falso o falsificado
- 4.7 Manipulación de PageRank
- 4.8 El modelo intencional surfista
- 5 Otros usos
- 6 nofollow
- 7 Degradación
- 8 Véase también
- 9 Notas
- 10 Referencias
- 11 Patentes relevantes
- 12 Enlaces externos
Descripción

PageRank es un Análisis de enlace algoritmo y se asigna una numérica ponderación a cada elemento de un hipervínculos conjunto de documentos, tales como la World Wide Web, con la finalidad de "medir" su importancia relativa dentro del conjunto. El algoritmo puede aplicarse a cualquier colección de entidades con recíproco citas y referencias. El peso numérico que se asigna a cualquier elemento E se conoce como el PageRank de E y se denota por  Otros factores como Autor Rank pueden contribuir a la importancia de una entidad.
Otros factores como Autor Rank pueden contribuir a la importancia de una entidad.
Un PageRank resulta de un algoritmo matemático basado en el Webgrafía, creado por todas las páginas Web a nivel mundial como nodos y hipervínculos como los bordes, teniendo en centros de autoridad de consideración como CNN.com o usa.gov. El valor fila indica una importancia de una página en particular. Un hipervínculo a una página cuenta como un voto de apoyo. El PageRank de una página se define recursivamente y depende del número y métrica de PageRank de todas las páginas que enlazan a él ("enlaces entrantes"). Una página que está ligada a muchas páginas con alto PageRank recibe un alto rango de sí mismo.
Se han publicado numerosos artículos académicos sobre PageRank desde Page y de Brin papel original.[5] En la práctica, el concepto de PageRank puede ser vulnerable a la manipulación. Se han realizado investigaciones en identificar falsamente influenciadas Escalafones de PageRank. El objetivo es encontrar un medio eficaz de ignorar enlaces de documentos con falsamente influenciadas PageRank.[6]
Otros algoritmos de clasificación basada en vínculos de páginas Web incluyen el Algoritmo HITS inventado por Jon Kleinberg (utilizado por Teoma y ahora Ask.com),[citación necesitada] la IBM Proyecto inteligente, la TrustRank algoritmo y la algoritmo de colibrí.
Historia
La idea de formular un problema de análisis de enlace como un valor propio problema fue probablemente primero sugerido en 1976 por Gabriel Pinski y Francis Narin, quien trabajó en cienciometría Ranking de las revistas científicas.[7] PageRank fue desarrollado en La Universidad de Stanford por Larry Page y Sergey Brin en 1996[8] como parte de un proyecto de investigación sobre un nuevo tipo de motor de búsqueda.[9] Sergey Brin tuvo la idea de que puede solicitarse información en la web en una jerarquía de "popularidad": una página ocupa el puesto más alto ya que hay más enlaces a él.[10] Fue co-escrito por Rajeev Motwani y Terry Winograd. El primer documento sobre el proyecto, describiendo el PageRank y el prototipo inicial de la Búsqueda de Google motor, fue publicado en 1998:[5] poco después, Page y Brin fundada Google Inc., la compañía detrás del motor de búsqueda Google. Mientras que los resultados sólo uno de muchos factores que determinan el ranking de búsqueda de Google, PageRank continúa proporcionan la base para todos de herramientas de búsqueda web de Google.[11]
El nombre "PageRank" juega con el nombre de desarrollador Larry Page, así como el concepto de un Página Web.[12] La palabra es una marca registrada de Google, y ha sido el proceso de PageRank patentado (US patente 6.285.999). Sin embargo, la patente es asignada a La Universidad de Stanford y no a Google. Google tiene licencia exclusiva derechos sobre la patente de la Universidad de Stanford. La Universidad recibió 1,8 millones de acciones de Google a cambio de uso de la patente; las acciones fueron vendidas en 2005 por $336 millones.[13][14]
PageRank fue influenciado por Análisis de citas, desarrollado por temprano Eugene Garfield en la década de 1950 en la Universidad de Pennsylvania y por Búsqueda de hiper, desarrollado por Massimo Marchiori en la Universidad de Padua. En el mismo año PageRank fue introducido (1998), Jon Kleinberg publicó su obra importante en HITS. Los fundadores de Google citan Garfield, Marchiori y Kleinberg en sus documentos originales.[5][15]
Un motor de búsqueda pequeño llamado"RankDex"de servicios de información de IDD diseñado por Robin Li fue, desde 1996, ya explorando una estrategia similar para el sitio puntaje y ranking de página.[16] La tecnología de RankDex podría ser patentada por 1999[17] y utilizado más adelante cuando Li fundó Baidu en China.[18][19] Trabajo de Li sería ser referenciado por algunas de las patentes estadounidenses de Larry Page por sus métodos de búsqueda de Google.[20]
Algoritmo
El algoritmo PageRank salidas un distribución de probabilidad utilizado para representar la probabilidad de que una persona al azar o haga clic en enlaces llegará a cualquier página en particular. PageRank puede calcularse para las colecciones de documentos de cualquier tamaño. En varios trabajos de investigación se asume que la distribución se divide por igual entre todos los documentos de la colección al principio del proceso computacional. Los cómputos de PageRank requieren varias pasadas, llamados "repeticiones", a través de la colección para ajustar el PageRank aproximada valores más estrechamente reflejan el verdadero valor teórico.
Una probabilidad se expresa como un valor numérico entre 0 y 1. Una probabilidad 0,5 comúnmente se expresa como un "50% de posibilidades" de algo. Por lo tanto, un PageRank de 0,5 significa que es un 50% posibilidad de que una persona haga clic en un enlace al azar será dirigida al documento con el PageRank 0,5.
Algoritmo simplificado
Supongamos un pequeño universo de las cuatro páginas web: A, B, C y D. Enlaces de una página a sí mismo, o múltiples enlaces salientes de una sola página a otra página individual, son ignorados. PageRank es inicializada con el mismo valor para todas las páginas. En la forma original de PageRank, la suma de PageRank sobre todas las páginas fue el número total de páginas en la web en ese momento, así que cada página en este ejemplo tendría un valor inicial de 1. Sin embargo, las versiones posteriores de PageRank y el resto de esta sección, asuman un distribución de probabilidad entre 0 y 1. Por lo tanto, el valor inicial de cada página es de 0.25.
El PageRank transferido desde una página dada a los objetivos de sus enlaces salientes a la siguiente iteración se divide igualmente entre todos los enlaces salientes.
Si los enlaces sólo en el sistema eran de páginas B, C, y D Para A, cada enlace transferiría PageRank 0.25 a A en la siguiente iteración, para un total de 0,75.

¿Y si en cambio esa página B tenía un enlace a las páginas C y A, página C tenía un enlace a la página Ay la página D tenía enlaces a todas las páginas de tres. Por lo tanto, en la primera iteración, página B ¿podría pasar la mitad de su valor actual, o 0.125, página A y la otra mitad, o 0.125, página C. Página C ¿transferir todo su valor existente, 0.25, a la única página vincula a A. Desde D tenía tres enlaces salientes, trasladarían a un tercio de su valor actual, o aproximadamente 0.083, a A. A la finalización de esta iteración, página A tendrá un PageRank de 0.458.
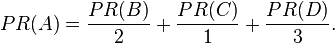
En otras palabras, el PageRank conferido por un enlace de salida es igual a la puntuación de PageRank del documento dividida por el número de enlaces salientes (L).

En el caso general, el valor de PageRank de cualquier página u puede expresarse como:
-
 ,
,
 ,
,
es decir, el valor de PageRank de una página u depende de los valores de PageRank para cada página v figuran en la Bu (el sistema que contiene todas las páginas enlazan a la página u), dividido por el número L(v) de enlaces de la página v.
Factor de amortiguación
La teoría de PageRank sostiene que un surfista imaginario que al azar es hacer clic en enlaces eventualmente dejará de clic. La probabilidad, en cualquier paso, que la persona continúe es un factor de amortiguación d. Diversos estudios han probado diferentes factores de amortiguación, pero generalmente se asume que el factor de amortiguación se establecerá alrededor de 0,85.[5]
El factor de amortiguación se resta de 1 (y en algunas variantes del algoritmo, el resultado se divide por el número de documentos (N) de la colección) y este término se agrega al producto del factor de amortiguación y la suma de las puntuaciones de PageRank entrantes. Es decir

¿PageRank de cualquier página se deriva en gran parte el PageRank de otras páginas. El factor de amortiguación ajusta el valor derivado hacia abajo. El documento original, sin embargo, dio la siguiente fórmula, que ha conducido a una cierta confusión:

La diferencia entre ellos es que los valores de PageRank en la primera fórmula definitiva a uno, mientras que en la segunda fórmula cada PageRank se multiplica por N y la suma se convierte en N. Una declaración en papel de Page y de Brin que "la suma de PageRank todo es uno"[5] y reclamaciones presentadas por otros empleados de Google[21] apoyo la primera variante de la fórmula anterior.
Page y Brin confunden las dos fórmulas en su papel más popular "La anatomía de un a gran escala hipertextual motor de búsqueda", donde afirmaron equivocadamente que la última fórmula formó una distribución de probabilidad sobre las páginas web.[5]
Google PageRank partituras vuelve a calcular cada vez rastrea la Web y reconstruye su índice. Google aumenta el número de documentos en su colección, la aproximación inicial de PageRank disminuye para todos los documentos.
La fórmula utiliza un modelo de un surfista al azar ¿Quién se aburre después de varios clics y cambia a una página aleatoria. El valor de PageRank de una página refleja la posibilidad de que el internauta al azar aterrizará en esa página haciendo clic en un enlace. Puede entenderse como una Cadena de Markov en el cual los Estados son páginas, y las transiciones, que son todas igualmente probables, son los vínculos entre páginas.
Si no dispone de una página enlaces a otras páginas, se convierte un fregadero y por lo tanto finaliza el proceso de navegación al azar. Si el internauta al azar llega a una página de fregadero, recoge otro URL al azar y continúa navegando otra vez.
Al calcular PageRank, páginas sin vínculos salientes se asumen para vincular a todas las demás páginas de la colección. Su puntuación de PageRank por lo tanto se divide uniformemente entre todas las demás páginas. En otras palabras ser justos con páginas que no se hunde, estas transiciones al azar se añaden a todos los nodos de la red, con una probabilidad residual suele establecer d = 0.85, Estimado a partir de la frecuencia que un surfista promedio utiliza la función bookmark de su navegador.
Así, la ecuación es como sigue:

donde 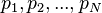 son las páginas bajo consideración,
son las páginas bajo consideración, 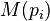 es el conjunto de páginas que enlazan con
es el conjunto de páginas que enlazan con 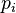 ,
,  es el número de enlaces salientes en la página
es el número de enlaces salientes en la página 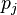 , y N es el número total de páginas.
, y N es el número total de páginas.
Los valores de PageRank son las entradas de la izquierda dominante cuadráticos de modificado matriz de adyacencia. Esto hace que una métrica especialmente elegante PageRank: es el vector propio
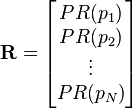
donde R es la solución de la ecuación
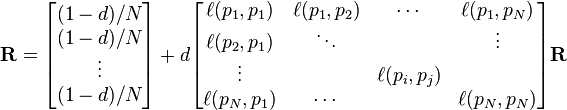
donde la función de adyacencia 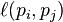 es 0 si página no enlaza con y normalizó tal que, para cada uno j
es 0 si página no enlaza con y normalizó tal que, para cada uno j
-
 ,
,
 ,
,
es decir, los elementos de cada columna suma hasta 1, así que la matriz es un matriz estocástica (para más detalles, véase el cómputo sección siguiente). Por lo tanto esto es una variante de la centralidad cuadráticos medida utilizada comúnmente en Análisis de redes.
Debido a la gran eigengap de la matriz de adyacencia modificada anterior,[22] los valores de los PageRank cuadráticos se pueden aproximar a dentro de un alto grado de precisión dentro de sólo unas pocas iteraciones.
Como resultado de Teoría de Markov, puede ser demostrado que el PageRank de una página es la probabilidad de llegar a esa página después de un gran número de clics. Esto sucede al mismo  donde
donde  es el expectativa el número de clics (o saltos al azar) requiere que desde la página volver a sí mismo.
es el expectativa el número de clics (o saltos al azar) requiere que desde la página volver a sí mismo.
Una de las principal desventajas de PageRank es que favorece mayores páginas. Una nueva página, incluso una muy buena, no tendrá muchos enlaces a menos que es parte de un sitio (un sitio siendo densamente conectado un conjunto de páginas, tales como Copro).
Se han propuesto varias estrategias para acelerar el cómputo de PageRank.[23]
Han empleado diversas estrategias para manipular el PageRank en esfuerzos concertados para mejorar el ranking de resultados de búsqueda y monetizar enlaces publicitarios. Estas estrategias han impactado severamente la fiabilidad del concepto de PageRank[citación necesitada] que pretende determinar qué documentos son en realidad muy valorados por la comunidad Web.
Desde diciembre de 2007, cuando empezó a activamente penalizar a sitios de venta pagado enlaces de texto, Google ha combatido granjas de enlace y otros esquemas diseñados para inflar artificialmente PageRank. ¿Cómo Google identifica enlace granjas y otras herramientas de manipulación de PageRank es entre de Google secretos comerciales.
Cómputo
PageRank puede ser computado iterativamente o algebraico. El método iterativo puede considerarse como el iteración de la energía método[24][25] o el método de la energía. Al realizar las operaciones matemáticas básicas son idénticas.
Iterativo
En  , se supone una distribución de probabilidad inicial, generalmente
, se supone una distribución de probabilidad inicial, generalmente
-
 .
.
 .
.
En cada paso de tiempo, la computación, como se detalla más arriba, los rendimientos
-
 ,
,
 ,
,
o en notación de matriz
-
 , (*)
, (*)
 , (*)
, (*)
donde 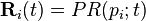 y
y  es el vector columna de longitud
es el vector columna de longitud  los únicos que contienen.
los únicos que contienen.
La matriz 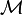 se define como
se define como

es decir,
-
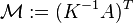 ,
,
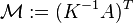 ,
,
donde  denota el matriz de adyacencia del gráfico y
denota el matriz de adyacencia del gráfico y 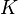 es la matriz diagonal con el outdegrees en la diagonal.
es la matriz diagonal con el outdegrees en la diagonal.
El cómputo termina cuando para algunas pequeñas 
-
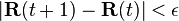 ,
,
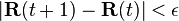 ,
,
es decir, cuando se asume convergencia.
Algebraica
Para 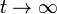 (es decir, en el estado estacionario), Lee la ecuación anterior (*)
(es decir, en el estado estacionario), Lee la ecuación anterior (*)
-
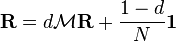 . (**)
. (**)
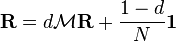 . (**)
. (**)
La solución está dada por
-
 ,
,
 ,
,
con el matriz identidad  .
.
La solución existe y es única para  . Esto se puede ver al notar que es por la construcción de un matriz estocástica y por lo tanto tiene un valor propio igual a uno como consecuencia de la Teorema de Perron-Frobenius.
. Esto se puede ver al notar que es por la construcción de un matriz estocástica y por lo tanto tiene un valor propio igual a uno como consecuencia de la Teorema de Perron-Frobenius.
Método de la energía
Si la matriz es una probabilidad de transición, es decir, columna-estocástico con sin columnas que consta de sólo ceros y 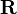 es una distribución de probabilidad (es decir,
es una distribución de probabilidad (es decir, 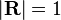 ,
,  donde
donde 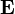 es la matriz de todos), es equivalente a la ecuación (*)
es la matriz de todos), es equivalente a la ecuación (*)
-
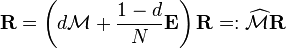 . (***)
. (***)
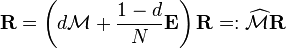 . (***)
. (***)
Por lo tanto PageRank es el principal vector propio de  . Una manera rápida y fácil de calcular esto es utilizando el método de la energía:: a partir de un vector arbitrario
. Una manera rápida y fácil de calcular esto es utilizando el método de la energía:: a partir de un vector arbitrario  , el operador se aplica en la sucesión, es decir,
, el operador se aplica en la sucesión, es decir,
-
 ,
,
 ,
,
hasta
-
 .
.
 .
.
Tenga en cuenta que en la ecuación (*) la matriz del lado derecho en el paréntesis puede interpretarse como
-
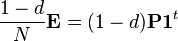 ,
,
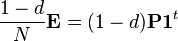 ,
,
donde 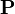 es la primera distribución de probabilidad. En el caso actual
es la primera distribución de probabilidad. En el caso actual
-
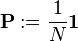 .
.
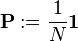 .
.
Por último, si tiene columnas con sólo valores cero, se deberá cambiar con el vector de probabilidad inicial . En otras palabras
-
 ,
,
 ,
,
donde la matriz  se define como
se define como
-
 ,
,
 ,
,
con
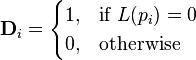
En este caso, los anteriores dos cómputos utilizando sólo dan el mismo PageRank si sus resultados son normalizados:
-
 .
.
 .
.
PageRank MATLAB/Octava implementación
Matriz de adyacencia % parámetro M donde M_i, j representa el enlace de 'j' de 'yo', tal que para todos 'j' % suma (i, M_i, j) = 1 % Parámetro d factor de amortiguamiento % Parámetro v_quadratic_error error cuadrático para v % V retorno, un vector de filas que v_i es la i-ésima fila de [0, 1] función [v] = Rank(M, v_quadratic_error d,) N = tamaño(M, 2); % N es igual a la mitad del tamaño de M v = Rand(N, 1); v = v. / norma(v, 2); last_v = Queridos(N, 1) * INF; M_hat = (d. * M) + (((1 -d) / N) .* Queridos(N, N)); al mismo tiempo(norma(v - last_v, 2) > v_quadratic_error) last_v = v; v = M_hat * v; v = v. / norma(v, 2); final endfunction función [v] = rank2(M, v_quadratic_error d,) N = tamaño(M, 2); % N es igual a la mitad del tamaño de M v = Rand(N, 1); v = v. / norma(v, 1); % Ahora es L1, L2 no last_v = Queridos(N, 1) * nnA; M_hat = (d. * M) + (((1 -d) / N) .* Queridos(N, N)); al mismo tiempo(norma(v - last_v, 2) > v_quadratic_error) last_v = v; v = M_hat * v; % eliminar la norma L2 de la PR iterada final endfunction
Ejemplo del código que llama a la función rango definida anteriormente:
M = [0 0 0 0 1 ; 0.5 0 0 0 0 ; 0.5 0 0 0 0 ; 0 1 0.5 0 0 ; 0 0 0.5 1 0]; Rank(M, 0,80, 0.001)
En este ejemplo toma 13 iteraciones para converger.
La siguiente es una prueba que rank.m es incorrecta. Se basa en el primer ejemplo gráfico. Mi entendimiento es que rank.m utiliza la norma mal en la entrada, luego sigue renormalize L2, que es innecesario.
% Representa el gráfico ejemplo, correctamente normalizado y contabilidad para fregaderos (nodo) % por permitir que la transición eficazmente al azar 100% del tiempo, incluyendo a sí mismo. % Mientras que RANK.m en realidad no hacerlo incorrectamente, no muestra exactamente cómo uno debe % mango fregadero nodos (una posible solución sería una transición automática de 1.0), que no % dará el resultado correcto. test_graph = ... [ 0.09091 0.00000 0.00000 0.50000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000; 0.09091 0.00000 1.00000 0.50000 0.33333 0.50000 0.50000 0.50000 0.50000 0.00000 0.00000; 0.09091 1.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000; 0.09091 0.00000 0.00000 0.00000 0.33333 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000; 0.09091 0.00000 0.00000 0.00000 0.00000 0.50000 0.50000 0.50000 0.50000 1.00000 1.00000; 0.09091 0.00000 0.00000 0.00000 0.33333 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000; 0.09091 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000; 0.09091 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000; 0.09091 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000; 0.09091 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000; 0.09091 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 ] PR = Rank(test_graph, 0,85, 0.001) % INCORRECTO no se normaliza. % 0.062247 % 0.730223 % 0.650829 % 0.074220 % 0.153590 % 0.074220 % 0.030703 % 0.030703 % 0.030703 % 0.030703 % 0.030703 PR / norma(RRN1) Una vez correcta % normalizado. Todavía no sé por qué ocurre la normalización L2 % (v = v/norm(v, 2)) % 0.032781 % 0.384561 % 0.342750 % 0.039087 % 0.080886 % 0.039087 % 0.016170 % 0.016170 % 0.016170 % 0.016170 % 0.016170 PR = rank2(test_graph, 0,85, 0.001) % CORRECTO, sólo requiere entrada normalización PR % (Asegúrese de que resume a 1.0) % 0.032781 % 0.384561 % 0.342750 % 0.039087 % 0.080886 % 0.039087 % 0.016170 % 0.016170 % 0.016170 % 0.016170 % 0.016170
Eficiencia
Según el marco utilizado para realizar el cómputo, la exacta aplicación de los métodos y la precisión requerida del resultado, el tiempo de cómputo de estos métodos puede variar grandemente.
Variaciones
PageRank de un gráfico sin señas
El PageRank de una sin señas gráfico G estadísticamente está cerca de la distribución de grado del gráfico G,[26] Pero generalmente no son idénticos: Si R es el vector de PageRank definido anteriormente, y D es el vector de la distribución de grado

donde  denota el grado de vértice , y E es el conjunto de borde del gráfico y, luego, con
denota el grado de vértice , y E es el conjunto de borde del gráfico y, luego, con  , por:[27]
, por:[27]

es decir, el PageRank de un gráfico sin señas es igual al vector de la distribución de grado si y sólo si el gráfico es regular, es decir, cada vértice tiene el mismo grado.
Algoritmo distribuido para el cómputo de PageRank
Hay simple y rápido basado en paseo aleatorio algoritmos distribuidos para calcular el PageRank de los nodos de una red.[28] Presentan un algoritmo simple que toma  rondas con alta probabilidad en cualquier gráfico (dirigido o no dirigida), donde n es el tamaño de la red y es el (probabilidad de reajuste
rondas con alta probabilidad en cualquier gráfico (dirigido o no dirigida), donde n es el tamaño de la red y es el (probabilidad de reajuste también se llama como factor de amortiguación) utilizados en el cómputo de PageRank. También presentan un algoritmo más rápido que lleva
también se llama como factor de amortiguación) utilizados en el cómputo de PageRank. También presentan un algoritmo más rápido que lleva  rondas en gráficos sin señas. Dos de los algoritmos anteriores son escalables, como cada nodo procesa y envía sólo pequeñas (polylogarithmic en n, el tamaño de la red) número de bits por ronda. Para los gráficos dirigidos, presentan un algoritmo que tiene una duración de
rondas en gráficos sin señas. Dos de los algoritmos anteriores son escalables, como cada nodo procesa y envía sólo pequeñas (polylogarithmic en n, el tamaño de la red) número de bits por ronda. Para los gráficos dirigidos, presentan un algoritmo que tiene una duración de 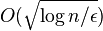 , pero requiere un polinomio número de bits a procesados y enviados por nodo en una ronda.
, pero requiere un polinomio número de bits a procesados y enviados por nodo en una ronda.
Google Toolbar
El Google Toolbarde PageRank característica muestra PageRank de una página visitada como un número entero entre 0 y 10. Los sitios web más populares tienen un PageRank de 10. Al menos tiene un PageRank de 0. Google no ha revelado el método para la determinación de un valor de PageRank de la barra de herramientas, que debe ser considerado sólo una indicación aproximada del valor de un sitio web específico.
PageRank mide el número de sitios que enlazar a una página en particular.[29] El PageRank de una página en particular más o menos se basa en la cantidad de enlaces entrantes, así como el PageRank de las páginas de los enlaces. El algoritmo también incluye otros factores como el tamaño de una página, el número de cambios, el tiempo ya que se actualiza la página, el texto en titulares y el texto en textos de anclaje con hipervínculos.[10]
PageRank de la barra de herramientas Google se actualiza con frecuencia, así los valores demuestra a menudo están desfasados.
SERP Rank
El Página de resultados del motor de búsqueda (SERP) es el resultado devuelto por un motor de búsqueda en respuesta a una pregunta clave. La SERP consiste en una lista de enlaces a páginas web con fragmentos de texto asociado. El rango SERP de una página web se refiere a la colocación del enlace correspondiente en el SERP, donde la colocación más alta significa mayor rango SERP. El rango SERP de una página web es una función no sólo de su PageRank, sino de un conjunto de factores (más de 200), relativamente grande y continuamente ajustado.[30] Optimización del search engine (SEO) está dirigido a influir en el rango SERP para un sitio web o un conjunto de páginas web.
Posicionamiento de una página web en Google SERPs para una palabra clave depende de la pertinencia y la reputación, también conocida como autoridad y popularidad. PageRank es indicación de Google de su evaluación de la reputación de una página web: es no-palabras clave específicas. Google utiliza una combinación de página web y el sitio web de la autoridad para determinar la autoridad general de una página web compitiendo por una palabra clave.[31] El PageRank de la Página Web de un sitio web es la mejor indicación que Google ofrece para la autoridad de la Página Web.[32]
Después de la introducción de Google Places en la corriente orgánica SERP, numerosos otros factores además de PageRank afectan ranking un negocio en resultados de negocios locales.[33]
Directorio de Google PageRank
El Directorio de Google PageRank fue una medida de 8 unidades. A diferencia de la barra de herramientas de Google, que demuestra un valor numérico PageRank mouseover de la barra verde, el directorio de Google sólo aparece la barra, nunca los valores numéricos. Directorio de Google fue cerrada el 20 de julio de 2011.[34]
PageRank falso o falsificado
En el pasado, fue manipulado fácilmente el PageRank se muestra en la barra de herramientas. Redirección de una página a otra, ya sea mediante una HTTP 302 respuesta o una "actualización" etiqueta meta, causó la página de origen adquirir el PageRank de la página de destino. Por lo tanto, una nueva página con PR 0 y sin enlaces entrantes podría haber adquirido PR 10 redirigiendo a la página de inicio de Google. Esto suplantación de identidad la técnica fue una vulnerabilidad conocida. Suplantación de identidad generalmente puede ser detectado por realizar una búsqueda en Google para una dirección URL de la fuente; Si la dirección URL de un sitio totalmente diferente se muestra en los resultados, la última URL puede representar el destino de una redirección.
Manipulación de PageRank
Para optimización del search engine propósitos, algunas compañías ofrecen vender alto PageRank enlaces para webmasters.[35] Como enlaces de páginas más alto-PR se creen que son más valiosos, tienden a ser más caro. Puede ser una estrategia de marketing eficaces y viable para comprar anuncios de enlace en páginas de contenido de calidad y sitios relevantes para dirigir el tráfico y aumentar la popularidad de un webmaster. Sin embargo, Google ha advirtió públicamente webmasters que si son o fueron descubiertas vendiendo enlaces con el fin de conferir PageRank y reputación, sus vínculos será devaluados (cuenta en el cálculo del PageRank de otras páginas). La práctica de la compra y venta de enlaces es debatida intensamente en toda la comunidad Webmaster. Google informa webmasters para usar el nofollow Atributo HTML valor de enlaces patrocinados. Según Matt Cutts, Google está preocupado por webmasters que intentan el sistema de juegoy reducir la calidad y relevancia de los resultados de búsqueda de Google.[35]
El modelo intencional surfista
El algoritmo PageRank original refleja el modelo denominado surfista al azar, lo que significa que el PageRank de una página en particular se deriva de la probabilidad teórica de visitar esa página, haga clic en enlaces al azar. Se llama un modelo de clasificación de página que refleja la importancia de una página en particular como una función de cuántas visitan reales lo recibe por los usuarios reales del modelo intencional surfista.[36] La barra Google envía información a Google por cada página visitada y tal modo proporciona una base para calcular PageRank basado en el modelo de surfista intencional. La introducción de la nofollow atributo por Google para combatir Spamdexing tiene el efecto secundario que webmasters comúnmente utilizarlo en enlaces salientes para aumentar su PageRank. Esto provoca una pérdida de enlaces reales para los rastreadores Web a seguir, con lo que el algoritmo PageRank original basado en el modelo al azar surfista potencialmente poco fiable. Utilizando información sobre los usuarios de navegación hábitos siempre por el Google toolbar en parte compensa la pérdida de información causada por la nofollow atributo. El SERP rango de una página, que determina la colocación real de una página en los resultados de la búsqueda, se basa en una combinación del modelo aleatorio surfista (PageRank) y el modelo de surfista intencional (hábitos de navegación) además de otros factores.[37]
Otros usos
Las matemáticas de PageRank son completamente generales y se aplican a cualquier gráfico o red en cualquier dominio. Por lo tanto, PageRank es ahora utilizan regularmente en bibliometría, social e información de análisis de red y para la predicción de enlace y recomendación. Incluso se utiliza para el análisis de sistemas de redes de carreteras, así como biología, química, Neurociencia y física.[38]
Personalizada PageRank es utilizado por Twitter para presentar a los usuarios con otras cuentas que deseen seguir.[39]
Swiftypede producto de búsqueda sitio construye un "PageRank es sitios Web específicos para cada" mirando las señales de cada sitio web de importancia y priorización de contenidos basados en factores tales como el número de enlaces desde la página de inicio.[40]
Una versión de PageRank se ha propuesto recientemente como un reemplazo para el tradicional Institute for Scientific Information (ISI) factor de impacto,[41] e implementado en Eigenfactor así como en SCImago. En lugar de simplemente contar total citación a una revista, la "importancia" de cada citación se determina en una moda de PageRank.
Un nuevo uso similar de PageRank es rango académicos programas de doctorado con base en sus registros de colocar a sus graduados en las posiciones de la facultad. En términos de PageRank, departamentos académicos enlazan uno al otro mediante la contratación de su Facultad de uno al otro (y de ellos mismos).[42]
PageRank ha sido utilizado para clasificar espacios o calles para predecir cuánta gente (los peatones o vehículos) viene a los espacios individuales o calles.[43][44] En semántica léxica ha sido utilizado para realizar Desambiguación del sentido de la palabra,[45] Similitud semántica,[46] y también para clasificar automáticamente WordNet synsets según lo fuerte que poseen una determinada propiedad semántica, como positividad o negatividad.[47]
A Rastreador web puede utilizar el PageRank como uno de un número de indicadores de importancia que se utiliza para determinar qué dirección URL a visitar durante un rastreo de la web. Uno de los primeros documentos de trabajo [48] que fueron utilizados en la creación de Google es Eficiente arrastrándose a través de URL pedidos,[49] que aborda el uso de un número de mediciones de diferente importancia para determinar cuán profundamente y cómo se mete mucho de un sitio de Google. PageRank se presenta como uno de un número de estas métricas de importancia, aunque hay otros listados como el número de enlaces entrantes y salientes para una dirección URL y la distancia desde el directorio raíz de un sitio a la URL.
El PageRank puede usarse también como un metodología para medir el impacto aparente de una comunidad como la Blogosfera en la Web global. Este enfoque utiliza por lo tanto el PageRank para medir la distribución de la atención en la reflexión de la Red sin escala paradigma.
En un ecosistema, una versión modificada del PageRank puede utilizarse para determinar las especies que son esenciales para la salud continua del medio ambiente.[50]
Para el análisis de redes de proteínas en biología PageRank es también una herramienta útil.[51] [52]
En 2005, en un estudio piloto en Pakistán, Democracia profunda estructural, SD2[53][54] fue utilizado para la selección de liderazgo en un grupo de agricultura sostenible llamado contacto juvenil. Utiliza SD2 PageRank para el procesamiento del proxy transitivo votos, con las restricciones adicionales de exigiendo al menos dos proxies iniciales por el votante y todos los votantes son candidatos de proxy. Las variantes más complejas puede ser construido en la cima de SD2, como agregar especialista proxies y votos directos para temas específicos, pero SD2 como el sistema subyacente de paraguas, los mandatos generalista proxies deben usarse siempre.
nofollow
A principios de 2005, Google implementó un nuevo valor "nofollow",[55] para el REL atributos de los elementos de enlace y ancla HTML, para que los desarrolladores web y bloggers puede hacer enlaces que Google no considerará a los efectos de PageRank — son enlaces que ya no constituyen un "voto" en el sistema de PageRank. En un intento de ayudar a combatir se añadió la relación nofollow Spamdexing.
Por ejemplo, personas previamente podrían crear muchos puestos de tablero de mensajes con enlaces a su sitio web para inflar artificialmente su PageRank. Con el valor nofollow, tablero de mensajes los administradores puede modificar su código para insertar automáticamente "rel = 'nofollow'" a todos los hipervínculos en puestos de trabajo, evitando PageRank de ser afectado por esos postes de concreto. Este método de evitar, sin embargo, también tiene varios inconvenientes, como la reducción del valor de enlace de comentarios legítimos. (Ver: Spam en los blogs de #nofollow)
En un esfuerzo para controlar manualmente el flujo de PageRank entre páginas dentro de un sitio web, muchos webmasters práctica lo que se conoce como esculpir el PageRank[56]— que es el acto de colocar estratégicamente el atributo nofollow en ciertos enlaces internos de una página web con el fin de embudo PageRank hacia esas páginas considera más importante el webmaster. Esta táctica se ha utilizado desde la creación del atributo nofollow, pero ya no puede ser efectiva desde que Google anunció que bloquea la transferencia de PageRank con nofollow no redirigir ese PageRank otros enlaces.[57]
Degradación
Una vez estaba disponible para los responsables del sitio verificado a través de la interfaz de Google Webmaster Tools PageRank. Sin embargo el 15 de octubre de 2009, un empleado de Google confirmó que la compañía había quitado PageRank de su Herramientas para webmasters sección, diciendo que "nosotros hemos estado diciendo a la gente durante mucho tiempo que ellos no deberían centrarse en PageRank tanto. Muchos propietarios de sitios parecen pensar que es la métrica más importante para ellos en la pista, que simplemente no es verdad."[58] Además, no está disponible en de Google PageRank el indicador Cromo Explorador.
El rango visible de la página se actualiza muy infrecuentemente. Ultima actualización en noviembre de 2013. En octubre de 2014 Matt Cutts anunció que no vendría otra actualización de pagerank visible.[59]
PageRank es ahora uno de 200 ranking factores que Google utiliza para determinar la popularidad de una página. Google Panda es una de las otras estrategias de que Google se basa ahora en popularidad rango de páginas. Aunque ya no es directamente importante de PageRank SEO efectos, la existencia de espalda-enlaces desde sitios web más populares sigue a una página web más arriba en los rankings de búsqueda.[60]
Véase también
- EigenTrust — un algoritmo PageRank descentralizado
- Bomba de Google
- Búsqueda de Google
- Matriz de Google
- Google Panda
- VisualRank -Aplicación de PageRank de Google búsqueda de imagen
- Algoritmo de colina
- Vínculo de amor
- Métodos de enlace Web
- Método de la energía — el algoritmo iterativo cuadráticos permite calcular PageRank
- Optimización del search engine
- SimRank — una medida de similitud de objeto a objeto basado en modelo al azar-surfer
- Sensible a la temática PageRank
- TrustRank
- Webgrafía
- CheiRank
- Google pingüino
- Colibrí de Google
Notas
- ^ "Centro de prensa de Google: datos divertidos". www.google.com. archivado desde el original el 2009-04-24.
- ^ "Hechos sobre Google y la competencia". Archivado de el original en 04 de noviembre de 2011. 12 de julio 2014.
- ^ https://www.google.com/competition/howgooglesearchworks.html. Falta o vacío
|title =(Ayuda) - ^ Sullivan, Danny. "¿Qué es Google PageRank? Una guía para buscadores y Webmasters". Search Engine Land.
- ^ a b c d e f Brin, S.; Página, L. (1998). "La anatomía de un motor de búsqueda Web hipertextual a gran escala" (PDF). Redes de computadores y sistemas ISDN 30:: 107-117. Doi:10.1016/S0169-7552 (98) 00110-X. ISSN0169-7552.
- ^ Gyöngyi, Zoltán; Berkhin, Pavel; Garcia-Molina, Héctor; Pedersen, Jan (2006), "Enlace detección de spam basada en la estimación de masa", Actas de la 32a Conferencia Internacional sobre Bases de datos muy grandes (VLDB ' 06, Seúl, Corea del sur) (PDF), págs. 439-450.
- ^ Gabriel Pinski y Francis Narin. "Influencia de la citación para agregados de revista de publicaciones científicas: teoría, con aplicación a la literatura de la física". Manejo y procesamiento de la información 12 (5): 297-312. Fewer:10.1016/0306-4573 (76) 90048-0.
- ^ Raphael Phan Chung Wei (2002-05-16). New Straits Times (Computimes; 2 ed). Falta o vacío
|title =(Ayuda);|Chapter =(ignoradoAyuda) - ^ Página de Larry, "PageRank: poner orden a la Web" en el Wayback Machine (archivado el 06 de mayo de 2002), Stanford Digital Library Project, charla. 18 de agosto de 1997 (archivado de 2002)
- ^ a b 187-página de estudio de la Universidad de Graz, Austria, incluye la nota que también los cerebros humanos se utilizan cuando se determina el page rank en Google
- ^ "Tecnología de Google". Google.com. 2011-05-27.
- ^ David Vise y Mark Malseed (2005). La historia de Google. p. 37. ISBN0-553-80457-X.
- ^ Lisa M. Krieger (01 de diciembre de 2005). "Stanford gana $ 336 millones de acciones de Google". San Jose Mercury News, citado por redOrbit. 2009-02-25.
- ^ Richard Brandt. "Puesta en marcha. Google tiene su ranura". Revista de Stanford. 2009-02-25.
- ^ Página, Lawrence; Brin, Sergey; Motwani, Rajeev y Winograd, Terry (1999). "El ranking de la citación de PageRank: poner orden a la Web". , publicado el 29 de enero de 1998 como un informe técnico PDF
- ^ Li Yanhong (06 de agosto de 2002). "Hacia un motor de búsqueda cualitativa". Internet Computing, IEEE (IEEE Computer Society) 2 (4): 24 – 29. Doi:10.1109/4236.707687.
- ^ USPTO, "Sistema de recuperación de documentos de hipertexto y método", Número de patente de los E.E.U.U.: 5920859, Inventor: Li Yanhong, fecha de presentación: 05 de febrero de 1997, fecha de emisión: 06 de julio de 1999
- ^ Greenberg, Andy, "El hombre que está latiendo Google", Forbes revista, 05 de octubre de 2009
- ^ "Sobre: RankDex", rankdex.com
- ^ CF. especialmente patentes de Lawrence Page, Estados Unidos 6.799.176 (2004) "método de recuento de documentos en una base de datos vinculado", 7.058.628 (2006) "método para la clasificación de nodo en una base de datos vinculado" y 7.269.587 (2007) "anotar documentos en una base de datos enlazado" 2011
- ^ Matt Cuttsdel blog: Directamente desde Google: lo que necesitas saber, vea la página 15 de sus diapositivas.
- ^ Taher Haveliwala y Sepandar Kamvar. (Marzo de 2003). "El segundo valor propio de la matriz de Google" (PDF). Informe técnico de la Universidad de Stanford:: 7056. arXiv:matemáticas/0307056. Bibcode:2003math... 7056N.
- ^ Gianna M. Del Corso, Antonio Gullí, Francesco Romani (2005). "Cómputo PageRank rápidamente mediante un sistema lineal disperso". Internet matemáticas. Lecture Notes in Computer Science 2 (3): 118. Doi:10.1007/978-3-540-30216-2_10. ISBN978-3-540-23427-2.
- ^ Arasu, A. y Novak, J. y Tomkins, A. y Tomlin, J. (2002). "PageRank cómputo y la estructura de la web: experimentos y algoritmos". Actas de la undécima Conferencia Internacional World Wide Web, cartel pista. Brisbane, Australia. págs. 107-117.
- ^ Massimo Franceschet (2010). "PageRank: parado sobre los hombros de gigantes". arXiv:1002.2858 [CS. IR].
- ^ Nicola Perra y Santo Fortunato.; Fortunato (septiembre de 2008). "Medidas de centralidad espectral en redes complejas". Phys Rev. E, 78 (3): 36107. arXiv:0805.3322. Bibcode:2008PhRvE... 78c6107P. Doi:10.1103/PhysRevE.78.036107.
- ^ Vince Grolmusz (2012). "Una nota sobre el PageRank de gráficos sin señas". ArXiv 1205 (1960): 1960. arXiv:1205.1960. Bibcode:2012arXiv1205.1960G.
- ^ Atish Das Sarma, Anisur Rahaman Molla, Gopal Pandurangan, Eli Upfal (2012). "Cómputo rápido PageRank distribuida". arXiv:1208.3071 [CS. DC, cs. DS].
- ^ Google Webmaster central discusión sobre PR
- ^ Fishkin, Rand; Jeff Pollard (02 de abril de 2007). "Search Engine Ranking factores - versión 2". seomoz.org. 11 de mayo, 2009.[¿fuente no fiable?]
- ^ Dover, D. Search Engine Optimization secretos Indianapolis. Wiley. 2011.
- ^ Viniker, D. La importancia de la detección de dificultad clave para SEO. Ed. Schwartz, M. Digital Guía volumen 5. Noticias de prensa. p 160 – 164.
- ^ "Ranking de anuncios: Ranking - Google lugares ayuda". Google.com. 2011-05-27.
- ^ Google Directorio #Google Directorio
- ^ a b "Cómo informar de enlaces pagados". mattcutts.com/blog. 14 de abril de 2007. 2007-05-28.
- ^ Jøsang, A. (2007). "Sistemas de reputación y confianza". En Aldini, A. Fundamentos de diseño y análisis de seguridad IV, conferencias Tutorial FOSAD 2006/2007. (PDF) 4677. Springer, LNCS 4677. págs. 209 – 245. Doi:10.1007/978-3-540-74810-6.
- ^ SEOnotepad. "El mito del ranking de Google Toolbar".
- ^ Gleich, David F. (18 de julio de 2014). "PageRank más allá de la Web". arXiv. 28 de julio 2014.
- ^ Pankaj Gupta, Ashish Goel, Jimmy Lin, Aneesh Sharma, Wang Dong y Reza Bosagh Zadeh WTF: El sistema que de seguir en Twitter, Actas de la XXII Conferencia Internacional en World Wide Web
- ^ Ja, Anthony (2012-05-08). "Y Combinator respaldado por Swiftype construye sitio de búsqueda que no está nada mal". TechCrunch. 2014-07-08.
- ^ Johan Bollen, Marko A. Rodriguez y Herbert Van de Sompel.; Rodríguez; Van De Sompel (diciembre de 2006). "Revista Status". Cienciometría 69 (3): 1030. arXiv:cs.GL/0601030. Bibcode:2006cs... 1030B. Doi:10.1145/1255175.1255273.
- ^ Benjamin M. Schmidt y Matthew M. Chingos (2007). "Ranking de programas de doctorado por la colocación: un nuevo método" (PDF). PD: ciencia política y política 40 (Julio): 523-529. Doi:10.1017/s1049096507070771.
- ^ B. Jiang (2006). "Ranking espacios para la predicción del movimiento humano en un entorno urbano". Revista Internacional de Ciencias de la información geográfica 23 (7): 823-837. arXiv:física/0612011. Doi:10.1080/13658810802022822.
- ^ B. Jiang, Yin y Zhao S. J. (2008). "Caminos naturales auto-organizados para predecir el flujo de tráfico: un estudio de sensibilidad". Diario de mecánica estadística: teoría y experimento. P07008 (7): 008. arXiv:0804.1630. Bibcode:2008JSMTE... 07..008J. Fewer:10.1088/1742-5468/2008/07/P07008.
- ^ Roberto Navigli, Mirella Lapata. "Un estudio Experimental de gráfica conectividad sin supervisión palabra sentido desambiguación". IEEE Transactions on análisis de patrones y de inteligencia de la máquina (TPAMI), 32, IEEE Press, 2010, págs. 678 – 692.
- ^ M. T. Pilehvar, D. Jurgens y R. Navigli. Alinear, ambigüedad y caminar: A unificado de enfoque para medir la similitud semántica.. In: de la 51 reunión anual de la Asociación de lingüística computacional (ACL 2013), Sofía, Bulgaria, 4 – 9 de agosto de 2013, págs. 1341-1351.
- ^ Andrea Esuli y Fabrizio Sebastiani. "PageRanking WordNet synsets: una aplicación a las propiedades de Opinion-Related" (PDF). En los procedimientos de la 35 reunión de la Asociación de lingüística computacional, Praga, CZ, 2007, págs. 424-431. 30 de junio, 2007.
- ^ "Documentos de trabajo sobre la creación de Google". Google. 29 de noviembre, 2006.
- ^ Cho, J., Garcia-Molina, H. y Page, L. (1998). "Eficiente arrastrándose a través de URL ordenando". Actas del VII Congreso en World Wide Web (Brisbane, Australia).
- ^ Burns, Judith (2009-09-04). "Google truco pistas de extinciones". Noticias de BBC. 2011-05-27.
- ^ Ivan G. y V. Grolmusz (2011). "Cuando la Web se encuentra con la celda: usando personalizada PageRank para el análisis de redes de interacción de proteínas". Bioinformática (Vol. 27, no. 3. pp. 405-407) 27 (3): 405-7. Doi:10.1093/Bioinformatics/btq680. PMID21149343.
- ^ D. Ivan banky y g. y V. Grolmusz (2013). "Igualdad de oportunidades para los nodos de la red de bajo grado: un método basado en PageRank para identificación de objetivos de proteína en gráficos metabólicos". PLoS One (Vol. 8, núm. 1. e54204) 8 (1): 405-7. Bibcode:2013PLoSO... 854204B. Doi:10.1371/Journal.pone.0054204. PMID23382878.
- ^ "Yahoo! Groups". Groups.Yahoo.com. 2013-10-02.
- ^ "OAI — autopoyético sistemas de información en las organizaciones modernas". CiteSeerX.ist.PSU.edu. 2013-10-02.
- ^ "Prevención de comentarios Spam". Google. El 1 de enero, 2005.
- ^ "Esculpir el PageRank: analizar el valor y los beneficios potenciales de la escultura PR con Nofollow". SEOmoz. 2011-05-27.
- ^ "Esculpir el PageRank". Mattcutts.com. 2009-06-15. 2011-05-27.
- ^ Susan Moskwa. "Distribución de PageRank extraído WMT". 16 de octubre, 2009
|Chapter =(ignoradoAyuda) - ^ Bartleman, Wil (2014-10-12). "Google Page Rank actualización no es va a venir". Admin administrado. 2014-10-12.
- ^ "Así que... ¿Crees que SEO ha cambiado". 19.03.14. Valores de fecha de llegada:
|Date =(Ayuda)
Referencias
- Altman, Alon; Moshe Tennenholtz (2005). "Sistemas de clasificación: los axiomas PageRank" (PDF). Actas de la sexta Conferencia ACM sobre comercio electrónico (CE-05). Vancouver, BC. 29 de septiembre 2014.
- Cheng, Alice; Eric J. Friedman (2006-06-11). "Manipulability de PageRank bajo Sybil estrategias" (PDF). Actas del primer taller sobre la economía de los sistemas en red (NetEcon06). Ann Arbor, Michigan. 2008-01-22.
- Farahat, Ayman; Reynolds, Thomas; Miller, Joel C.; Rae, Gregory y Ward, Lesley A. (2006). "Autoridad Rankings de HITS, PageRank y SALSA: existencia, unicidad y efecto de inicialización". SIAM Journal on Scientific Computing 27 (4): 1181 – 1201. Doi:10.1137/S1064827502412875.
- Haveliwala, Taher; Jeh, Glen y Sepandar, Sepandar (2003). "Una comparación analítica de enfoques para la personalización de PageRank" (PDF). Informe técnico de la Universidad de Stanford.
- Langville, Amy N.; Meyer, Carl D. (2003). "Encuesta: profundo PageRank". Internet matemáticas 1 (3).
- Langville, Amy N.; Meyer, Carl D. (2006). PageRank de Google y más allá: la ciencia del Search Engine Rankings. Princeton University Press. ISBN0-691-12202-4.
- Richardson, Matthew; Domingos, Pedro (2002). "El surfista inteligente: combinación probabilístico de enlace y contenido de la información en PageRank" (PDF). Actas de los avances en los sistemas de procesamiento de la información Neural 14.
Patentes relevantes
- PageRank US patente original — método para el nodo de clasificación en una base de datos vinculado— La patente número 6.285.999 — 04 de septiembre de 2001
- Patente de los E.E.U.U. PageRank — método de recuento de documentos en una base de datos vinculado— La patente número 6.799.176 — 28 de septiembre de 2004
- Patente de los E.E.U.U. PageRank — método para el nodo de clasificación en una base de datos vinculado— La patente número 7.058.628 – 06 de junio de 2006
- Patente de los E.E.U.U. PageRank — anotando los documentos en una base de datos vinculado— La patente número 7.269.587 — 11 de septiembre de 2007
Enlaces externos
- Nuestra búsqueda: Google tecnología por Google
- ¿Cómo Google encuentra la aguja en el pajar de la Web por la sociedad matemática americana
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||