Búsqueda de texto completo
|
|
Este artículo tiene varios problemas. Por favor ayuda mejorar o hablar de estos temas en la la página de discusión. (Aprender cómo y cuándo quitar estos mensajes de plantilla)
(Aprender cómo y cuándo quitar este mensaje de plantilla)
|
En recuperación de texto, búsqueda de texto completo se refiere a técnicas para buscar un solo computadora-almacena documento o una colección en un base de datos de texto completo. Búsqueda de texto completo se distingue de búsquedas basadas en metadatos de o en partes de los textos originales representadas en bases de datos (por ejemplo, títulos, resúmenes, secciones seleccionadas o referencias bibliográficas).
En una búsqueda de texto completo, un motor de búsqueda examina todas las palabras en cada documento almacenado en sus intentos para que coincida con el criterio de búsqueda (por ejemplo, texto especificado por el usuario). Técnicas de búsqueda de texto completo llegó a ser común en online bases de datos bibliográficas en la década de 1990.[verificación necesitada] Muchos programas de aplicaciones y sitios web (tales como procesamiento de textos software) proporciona capacidades de búsqueda de texto completo. Algunas web motores de búsqueda, tales como AltaVista, emplear técnicas de búsqueda de texto completo, mientras que otros índice sólo una parte de las páginas web por sus sistemas de indexación.[1]
Contenido
- 1 Indexación de direcciones
- 2 La precisión contra compensación de memoria
- 3 Problema positivo falso
- 4 Mejoras en el rendimiento
- 4.1 Mejora de herramientas de consulta
- 4.2 Algoritmos de búsqueda mejorada
- 5 Software
- 5.1 Software libre y de código abierto
- 5.2 Software privativo
- 6 Notas
- 7 Véase también
Indexación de direcciones
Cuando se trata de un pequeño número de documentos, es posible que el motor de búsqueda de texto completo explorar directamente el contenido de los documentos con cada uno consultauna estrategia llamada "serie de análisis. "Esto es lo que algunas herramientas, tales como grep, hacer la búsqueda.
Sin embargo, cuando el número de documentos para buscar es potencialmente grande, o la cantidad de consultas de búsqueda a realizar es considerable, el problema de búsqueda de texto completo a menudo se divide en dos tareas: indexación y búsqueda. La etapa de indexación escanear el texto de todos los documentos y crear una lista de términos de búsqueda (a menudo llamado un Índice, pero más correctamente llamado un concordancia). En la fase de búsqueda, al realizar una consulta específica, solamente el índice se hace referencia, en lugar del texto de los documentos originales.[2]
El indizador hará una entrada en el índice para cada término o palabra en un documento y posiblemente tenga en cuenta su posición relativa dentro del documento. Generalmente se ignora el indizador parar palabras (como "la" y "y") que son comunes y suficientemente significativos para ser útil en la búsqueda. Algunos indizadores también emplean el lenguaje específico derivados en las palabras ser indexadas. Por ejemplo, las palabras "unidades", "condujo" y "conducido" se grabará en el índice bajo la palabra del único concepto "unidad."
La precisión contra compensación de memoria
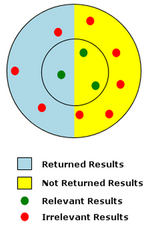
Recordar las medidas de la cantidad de relevantes resultados devueltos por una búsqueda, mientras que la precisión es la medida de la calidad de los resultados devueltos. Recordar la relación de resultados relevantes devuelve todos los resultados relevantes. Precisión es el número de resultados relevantes para el número total de resultados devueltos.
El diagrama a la derecha representa la búsqueda de una precisión baja, baja-memoria. En el diagrama los puntos rojo y verdes representan la población total de posibles resultados para una búsqueda determinada. Puntos rojos representan resultados irrelevantes y puntos verdes representan resultados relevantes. Relevancia se indica por la proximidad de los resultados de búsqueda para el centro del círculo interior. De todos los resultados posibles que se muestran, los que realmente fueron devueltos por la búsqueda se muestran sobre un fondo azul claro. En el ejemplo sólo uno de los resultados pertinente de tres posibles resultados relevantes fue devuelto, por lo que la memoria es una proporción muy baja de 1/3 o 33%. La precisión para el ejemplo es muy bajo 1/4 o 25%, ya que sólo uno de los cuatro resultados devueltos era relevante.[3]
Debido a las ambigüedades de lenguaje natural, sistemas de búsqueda de texto completo normalmente incluye opciones como parar palabras para aumentar la precisión y derivados para aumentar la memoria. Vocabulario controlado busca también ayuda a aliviar los problemas de precisión de baja por etiquetado documentos de tal manera que se eliminan ambigüedades. El compromiso entre precisión y memoria es simple: un aumento en la precisión puede bajar memoria general mientras que un aumento en memoria baja precisión.[4]
Problema positivo falso
Búsqueda de texto libre es probable recuperar muchos documentos que no son pertinentes a la la intención pregunta de búsqueda. Tales documentos se denominan falsos positivos (véase Error tipo I). La recuperación de documentos irrelevantes es causada a menudo por la ambigüedad inherente de lenguaje natural. En el diagrama de la muestra a la derecha, falsos positivos están representados por los resultados irrelevantes (puntos rojos) que fueron devueltos por la búsqueda (sobre un fondo azul claro).
Basado en las técnicas de clustering Bayesiano algoritmos pueden ayudar a reducir falsos positivos. Para un término de búsqueda de "banco", agrupamiento puede utilizarse para clasificar el universo de datos de documentos en la "Institución financiera", "Lugar para sentarse", "Lugar para guardar" etc.. Dependiendo de las ocurrencias de palabras correspondientes a las categorías, términos de búsqueda o un resultado de búsqueda se puede colocar en uno o más de las categorías. Esta técnica se está implementando ampliamente en las e-discovery dominio.[aclaración necesitada]
Mejoras en el rendimiento
Las deficiencias de la búsqueda de texto libre se han abordado en dos formas: por proporcionar a los usuarios herramientas que les permitan expresar sus preguntas de búsqueda más precisa y mediante el desarrollo de nuevos algoritmos de búsqueda que mejoran la precisión de la recuperación.
Mejora de herramientas de consulta
- Palabras clave. Creadores del documento (o indizadores entrenados) deberá proporcionar una lista de palabras que describan al tema del texto, incluyendo sinónimos de las palabras que describen a este tema. Palabras clave mejora la memoria, especialmente si la lista de palabras clave incluye una palabra de búsqueda que no está en el texto del documento.
- Búsqueda restringida a campo. Algunos motores de búsqueda permiten a los usuarios restringir la búsqueda de texto libre a un determinado campo dentro de un almacenado registro de datos, como "Título" o "Autor."
- Consultas booleanas. Búsquedas que utilizan Boolean operadores (por ejemplo, "enciclopedia" Y "en línea" NO "Encarta") puede aumentar notablemente la precisión de una búsqueda de texto libre. El Y operador dice, en efecto, «no recuperar cualquier documento a menos que contiene tanto de estos términos"la NO operador dice, en efecto, «no recuperar cualquier documento que contiene esta palabra."si la lista de recuperación recupera muy pocos documentos, la OR operador se puede utilizar para aumentar la memoria; Consideremos, por ejemplo, "enciclopedia" y "en línea" OR "Internet" no "Encarta". Esta búsqueda recuperará documentos sobre enciclopedias en línea que utilizan el término "Internet" en vez de "en línea" este aumento en la precisión es muy contraproducente ya que generalmente viene con una dramática pérdida de memoria.[5]
- Búsqueda de frase. Una búsqueda de frase coincide con sólo aquellos documentos que contengan una frase especifica, tales como "Copro, la enciclopedia libre."
- Búsqueda del concepto. Una búsqueda que se basa en conceptos de varias palabras, por ejemplo Procesamiento del término compuesto. Este tipo de búsqueda se ha vuelto popular en muchas soluciones de e-Discovery.
- Búsqueda de concordancia. La búsqueda de una concordancia produce una lista alfabética de todas las palabras principales que ocurren en un texto con su contexto inmediato.
- Búsqueda de proximidad. Una búsqueda de frase coincide con sólo aquellos documentos que contengan dos o más palabras separadas por un determinado número de palabras; una búsqueda de "Copro" WITHIN2 "gratis" recuperar sólo aquellos documentos en los que las palabras "Copro" y "gratis" ocurrir dentro de dos palabras de cada uno.
- Expresión regular. Una expresión regular emplea una consulta compleja pero de gran alcance Sintaxis de puede utilizarse para especificar las condiciones de recuperación con precisión.
- Búsqueda aproximada buscará los documentos que coincidan con los términos dados y algunas variaciones alrededor de ellos (usando por ejemplo edición distancia al umbral de la variación múltiple)
- Búsqueda por carácter comodín. Una búsqueda que sustituye uno o más caracteres en una consulta de búsqueda de carácter comodín, como un Asterisk. Por ejemplo, utilizando el asterisco en una consulta de búsqueda "s * n" encontrará "pecado", "hijo", "sol", etc. en un texto.
Algoritmos de búsqueda mejorada
El PageRank algoritmo desarrollado por Google da más importancia a los documentos a los que otros Páginas web han vinculado.[6] Ver Motor de búsqueda para obtener más ejemplos.
Software
La siguiente es una lista parcial de productos de software disponibles cuyo propósito predominante es realizar la indización de texto completo y búsqueda. Algunos de estos están acompañados de descripciones detalladas de su teoría de la operación o algoritmos internos, que pueden proporcionar la penetración adicional en la búsqueda de texto completo cómo se pueden lograr.
Software libre y de código abierto
- BaseX
- Clusterpoint la base de datos
- DataparkSearch
- Elasticsearch
- HT: / / Dig
- KinoSearch
- Lemur/Indri
- Lucene
- mnoGoSearch
- Searchdaimon
- Esfinge
- SWiSH-e
- Xapian
Software privativo
- Algolia
- Attivio
- Corporación de autonomía
- Búsqueda de azul
- Proyecto de Responsa de Ilan de la barra
- BRAINWARE
- BRS/Search
- Concepto de búsqueda limitada
- Dieselpoint
- dtSearch
- Endeca
- Exalead
- Funnelback
- Transferencia y búsqueda rápida
- Inktomi
- Locayta(su nombre a ATTRAQT en 2014)
- Lúcida imaginación
- MarkLogic
- SAP HANA[7]
- Swiftype
- Thunderstone Software LLC.
- Vivísimo
Notas
- ^ En la práctica, puede ser difícil determinar cómo funciona un motor de búsqueda determinado. El algoritmos de búsqueda realmente empleados por búsqueda en la web servicios se divulgan raramente completamente por temor a que los empresarios web posicionamiento en buscadores técnicas para mejorar su prominencia en las listas de recuperación.
- ^ Capacidades de sistema de búsqueda de texto completo Programa archivado 23 de diciembre de 2010, en el Máquina de Wayback.
- ^ Coles, Michael (2008). Pro Full-Text Search en SQL Server 2008 (Versión 1 ed.). Editorial Apress. ISBN 1-4302-1594-1.
- ^ B., Yuwono; Lee, D.L. (1996). Algoritmos de búsqueda y clasificación para localizar recursos en la World Wide Web. 12 Conferencia Internacional sobre datos de ingeniería (ICDE 96). p. 164.
- ^ Los estudios han demostrado repetidamente que la mayoría de usuarios no entienden los impactos negativos de búsquedas Booleanas.[1]
- ^ NOS A método asignan rangos de importancia a los nodos en una base de datos vinculada, como cualquier base de datos de documentos que contienen citas, la world wide web o cualquier otra base de datos de hipermedia. El rango asignado a un documento se calcula de las filas de los documentos lo citando. Además, la fila de un documento es... 6285999, Página, Lawrence, "Método para nodo en una base de datos enlazada", publicado el 09/01/1998, publicado 04/09/2001
- ^ https://www.martechadvisor.com/news/Databases-Big-Data/SAP-ADDS-hanabased-software-packages-to-IOT-portfolio/
Véase también
- Coincidencia de patrón y coincidencia de cadena
- Procesamiento del término compuesto
- Búsqueda empresarial
- Extracción de información
- Recuperación de información
- Búsqueda Facetada
- Lista de proveedores de búsqueda de empresa
- WebCrawler, primer motor de FTS
- Indexación del motor de búsqueda -Cómo los motores de búsqueda generan índices para búsqueda de texto completo de la ayuda
Otras Páginas
- Festi botnet
- Soterml
- Lau Lauritzen, Jr.
- Marketing Alliance
- David Montolieu, baron de St Hippolyte
- Municipio de Goshen, Condado de Mahoning, Ohio
- Hipotesis de funcionamiento resistencia
- CAN-SPAM Act de 2003
- NCR Corporation (redireccion de Corporacion caja registradora nacional)
- Que puedes sanar tu vida
- KeepVault