Base de datos
A base de datos es una colección organizada de datos. Los datos normalmente se organizan para los aspectos del modelo de la realidad de una manera que apoya los procesos que requieran información. Por ejemplo, modelar la disponibilidad de habitaciones en hoteles de una manera que apoya a encontrar un hotel con vacantes.
Sistemas de gestión de base de datos (DBMSs) son programas informáticos las aplicaciones que interactúan con el usuario, otras aplicaciones y la base de datos propia para capturar y analizar datos. Un DBMS polivalente está diseñado para permitir la definición, creación, consulta, actualización y administración de bases de datos. DBMS bien conocido incluyen MySQL, PostgreSQL, Microsoft SQL Server, Oracle, SAP y IBM DB2. Una base de datos no es generalmente portable a través de diferentes bases de datos, pero diferentes DBMSs pueden interoperar utilizando estándares tales como SQL y ODBC o JDBC para permitir que una sola aplicación trabajar con más de un DBMS. Sistemas de gestión de base de datos a menudo se clasifican según la modelo de base de datos que apoyan; todos los sistemas de base de datos más populares desde los años ochenta han apoyado la Modelo relacional representado por el SQL idioma. A veces un DBMS libremente se conoce como una 'base de datos'.
Contenido
- 1 Terminología y Resumen
- 2 Aplicaciones
- 3 Bases de datos generales y especiales
- 4 Historia
- 4.1 años sesenta, navegación DBMS
- 4.2 años setenta, DBMS relacional
- 4.3 Enfoque integrado
- 4.4 Finales de los setenta, DBMS SQL
- 4.5 años ochenta, en el escritorio
- 4.6 años ochenta, orientado a objetos
- 4.7 2000s, NoSQL y NewSQL
- 5 Investigación
- 6 Ejemplos
- 7 Diseño y modelado
- 7.1 Modelos
- 7.2 Vistas internas, conceptuales y externos
- 8 Idiomas
- 9 Rendimiento, seguridad y disponibilidad
- 9.1 Almacenamiento de información
- 9.1.1 Vistas materializadas
- 9.1.2 Replicación
- 9.2 Seguridad
- 9.3 Transacciones y concurrencia
- 9.4 Migración
- 9.5 Construcción, mantenimiento y ajuste
- 9.6 Backup y restore
- 9.7 Otros
- 9.1 Almacenamiento de información
- 10 Véase también
- 11 Referencias
- 12 Lectura adicional
- 13 Enlaces externos
Terminología y Resumen
Formalmente, "base de datos" refiere a los datos propios y estructuras de datos soporte. Se crean las bases de datos para manejar grandes cantidades de información por introducir, almacenar, recuperar y administrar esa información. Bases de datos se configuran para que un conjunto de programas de software proporciona todos los usuarios con acceso a todos los datos.
Un "sistema de gestión de base de datos" es una suite de software de computadora que proporciona la interfaz entre usuarios y una base de datos o bases de datos. Porque ellos están tan estrechamente relacionados, el término "base de datos" cuando se usa casualmente a menudo se refiere a un DBMS y manipula los datos.
Fuera del mundo del profesional tecnología de la información, el término base de datos a veces se usa informalmente para referirse a cualquier colección de datos (tal vez un hoja de cálculoTal vez incluso un índice de tarjeta). Este artículo se refiere sólo a bases de datos donde los requisitos de tamaño y uso requieren el uso de un sistema de gestión de base de datos.[1]
Las interacciones atendidas por más bases de datos existentes se dividen en cuatro grupos principales:
- Definición de datos – Definición de nuevas estructuras de datos para una base de datos, eliminación de las estructuras de datos de la base de datos, modificar la estructura de los datos existentes.
- Actualización – Insertar, modificar y eliminar datos.
- Recuperación – Obtener información para informes y consultas del usuario final o para el procesamiento de las aplicaciones.
- Administración – Registro y control de los usuarios, reforzar la seguridad de los datos, monitorear el desempeño, mantener la integridad de datos, con control de concurrencia y recuperación de información si el sistema falla.
Un DBMS es responsable de mantener la integridad y seguridad de los datos almacenados y para la recuperación de información si el sistema falla.
Su DBMS y una base de datos se ajustan a los principios de un determinado modelo de base de datos.[2] "Sistema de bases de datos" se refiere colectivamente a la modelo de base de datos, sistema de gestión de base de datos y base de datos.[3]
Físicamente, base de datos servidores son equipos dedicados que mantenga las actuales bases de datos y ejecutan sólo el DBMS y software relacionado. Suelen ser servidores de base de datos multiprocesador computadoras, con abundante memoria y RAID arreglos de discos utilizados para el almacenamiento estable. RAID se utiliza para la recuperación de datos si alguno de los discos falla. Aceleradores de hardware de base de datos, conectados a uno o más servidores a través de un canal de alta velocidad, también se utilizan en entornos de procesamiento de transacciones de gran volumen. Bases de datos se encuentran en el corazón de la mayoría aplicaciones de base de datos. Bases de datos pueden ser construidas alrededor de una costumbre multitarea núcleo con built-in redes apoyo, pero DBMS moderno normalmente dependen de un estándar Sistema operativo para proporcionar estas funciones.[citación necesitada] Desde DBMSs constituyen un significativo económico mercado, Computadoras y los proveedores de almacenamiento de información a menudo toman en cuenta los requisitos DBMS en sus propios planes de desarrollo.[citación necesitada]
Bases de datos y bases de datos pueden ser clasificados según el modelo de base de datos que soportan (tales como relacionales o XML), el tipo de computadora que correr en (de un clúster de servidores a un teléfono móvil), la lenguaje de consulta(s) utilizado para acceder a la base de datos (tales como SQL o XQuery), y su ingeniería interna, que afecta el desempeño, escalabilidad, la resiliencia y la seguridad.
Aplicaciones
|
|
En esta sección No lo hace Cite cualquier referencias o fuentes. (Marzo de 2013) |
Bases de datos se utilizan para apoyar las operaciones internas de las organizaciones y apuntalar las interacciones online con clientes y proveedores (véase Software para empresas).
Bases de datos se utilizan para sostener la información administrativa y datos más especializados, tales como datos de ingeniería o modelos económicos. Ejemplos de base de datos de aplicaciones incluyen computarizado Biblioteca sistemas, sistemas de reserva de vuelo e informatizadas sistemas de inventario de piezas.
Bases de datos generales y especiales
Un DBMS se ha convertido en un sistema de software complejo y su desarrollo en general, requiere miles de años-persona de esfuerzo de desarrollo.[4] Algunos DBMS para fines generales tales como Adabas, Oracle y DB2 han sido sometidos a las actualizaciones desde la década de 1970. DBMS propósito general apunta a satisfacer las necesidades de tantas aplicaciones como sea posible, que se suma a la complejidad. Sin embargo, el hecho de que su costo de desarrollo puede extenderse sobre un gran número de usuarios significa que a menudo son el método más rentable. Sin embargo, un DBMS polivalente no es siempre la solución óptima: en algunos casos un DBMS polivalente puede introducir gastos innecesarios. Por lo tanto, hay muchos ejemplos de sistemas que utilizan bases de datos especiales. Un ejemplo común es una Correo electrónico sistema: sistemas de correo electrónico están diseñados para optimizar el manejo de mensajes de correo electrónico y no necesitan porciones significativas de una funcionalidad polivalente de DBMS.
Tienen muchas bases de datos software de aplicación tiene acceso a la base de datos en nombre de los usuarios finales, sin exponer directamente a la interfaz DBMS. Los programadores de aplicaciones pueden usar un Protocolo de alambre directamente, o más probablemente a través de un interfaz de programación de aplicaciones. Diseñadores de bases de datos y administradores de bases de datos interactúan con el DBMS a través de interfaces dedicados a crear y mantener bases de datos de las aplicaciones y por lo tanto necesitan más conocimiento y comprensión acerca de cómo operan los DBMSs y interfaces externas de los DBMSs y afinar los parámetros.
Historia
Después de la tecnología progreso en las áreas de procesadores, memoria de la computadora, almacenamiento de la computadora y redes de computadores, los tamaños, capacidades y performance de bases de datos y sus respectivas bases de datos han crecido en órdenes de magnitud. El desarrollo de la tecnología de base de datos puede dividirse en tres épocas basados en el modelo de datos o estructura: navegación,[5] SQL /relacionalesy post-relacionales.
Los dos modelos de datos de navegación principios principales fueron la modelo jerárquico, cuyo máximo exponente es sistema IMS de IBM y el CODASYL (modelomodelo de red), implementado en un número de productos tales como IDMS.
El Modelo relacional, propuso por primera vez en 1970 por Edgar F. Codd, se apartó de esta tradición al insistir en que las aplicaciones deben buscar datos por contenido, y no siguiendo los enlaces. El modelo relacional emplea conjuntos de mesas de contabilidad-estilo, cada uno utilizado para otro tipo de entidad. Solamente en los mediados de los ochenta hardware de computación se hizo lo suficientemente potente como para permitir que el amplio despliegue de sistemas relacionales (bases de datos y aplicaciones). En la década de 1990, sin embargo, sistemas relacionales dominaban en todas las aplicaciones de procesamiento de datos a gran escala y a partir de 2014[actualización] siguen siendo dominantes, excepto en áreas de nicho. La lengua dominante de base de datos, SQL estandarizado para el modelo relacional, ha influido en lenguajes de base de datos para otros modelos de datos.[citación necesitada]
Bases de datos objeto se desarrollaron en la década de 1980 para superar los inconvenientes de desajuste de impedancia objeto-relacional, que condujo el acuñar el término "post-relacionales" y también el desarrollo de híbridos bases de datos objeto-relacionales.
La próxima generación de bases de datos post-relacionales en el 2000s tarde llegó a ser conocida como NoSQL bases de datos, introduciendo rápido tiendas de clave y valor y bases de datos orientada a documentos. Una competencia denominada "next-generation" NewSQL intentaron de bases de datos nuevas implementaciones que conservan el modelo relacional/SQL mientras que apunta para que coincida con el alto rendimiento de NoSQL comparado con DBMS relacional disponible comercialmente.
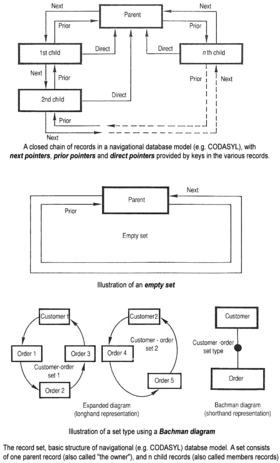
La introducción del término base de datos coincidió con la disponibilidad de almacenamiento de acceso directo (discos y tambores) desde mediados de 1960 en adelante. El término representa un contraste con los sistemas basados en cinta del pasado, permitiendo comparte uso interactivo en lugar de diario procesamiento por lotes. El Diccionario de Inglés Oxford CITES[6] un informe de 1962 por la Corporación de desarrollo del sistema de California como el primero en utilizar el término "base de datos" en un sentido técnico específico.
Como computadoras crecieron en velocidad y capacidad, surgieron una serie de sistemas de base de datos para fines generales; por mediados de 1960 había entrado un número de tales sistemas en uso comercial. Interés en un estándar comenzaron a crecer, y Charles Bachman, autor de un tal producto, los Almacén de datos integrado (IDS), fundó el "grupo de trabajo de base de datos" dentro de CODASYL, el grupo responsable de la creación y normalización de COBOL. En 1971 el grupo de trabajo de base de datos entregados sus estándares, que generalmente se conocen como el "enfoque CODASYL", y pronto una serie de productos comerciales basados en este enfoque entró en el mercado.
El enfoque CODASYL se basó en la navegación "manual" de un conjunto de datos enlazado que se formó en una gran red. Las aplicaciones podrían encontrar registros por uno de tres métodos:
- Uso de una clave principal (conocido como clave CALC, normalmente implementada por hashing)
- Navegando por las relaciones (llamadas juegos) de un registro a otro
- Análisis de todos los registros en un orden secuencial
Sistemas posteriores añadió B-Trees para proporcionar las rutas de acceso alternativo. Muchas bases de datos CODASYL agregan también un lenguaje de consulta muy sencillo. Sin embargo, en el recuento final, CODASYL fue muy compleja y requiere capacitación significativa y esfuerzo para producir aplicaciones útiles.
IBM también tenía su propio DBMS en 1968, conocido como Sistema de gestión de información (IMS). IMS fue un desarrollo de software escrito para la Programa Apolo en el Sistema/360. IMS fue generalmente similar en concepto a CODASYL, pero utiliza una estricta jerarquía para su modelo de navegación de datos en lugar de un modelo de red de CODASYL. Ambos conceptos más tarde pasó a denominarse bases de datos de navegación debido a la manera en que se accedió a datos y de Bachman 1973 Premio Turing presentación fue El programador como navegante. IMS se clasifica[¿por quién?] como un base de datos jerárquica. IDMS y Cincom Systems' TOTAL base de datos se clasifican como bases de datos de red. IMS permanece en uso a partir de 2014[actualización].[7]
años setenta, DBMS relacional
Edgar Codd trabajó en IBM en San Jose, California, en una de sus oficinas de rama que estaba involucrado principalmente en el desarrollo de disco duro sistemas. No estaba contento con el modelo de navegación del enfoque CODASYL, en particular la falta de un servicio "de búsqueda". En 1970, escribió una serie de papeles que se describe un nuevo enfoque a la construcción de base de datos que finalmente culminaron en la palada inicial Un modelo relacional de datos para grandes bancos de datos compartidos.[8]
En este papel, describió un nuevo sistema para almacenar y trabajar con grandes bases de datos. En lugar de registros se almacenan en algunos una especie de lista enlazada de los registros de forma libre como CODASYL, idea de Codd fue usar una "mesa"de los registros de longitud fija, con cada tabla utilizada para otro tipo de entidad. Un sistema de lista vinculada sería muy ineficiente al almacenar bases de datos "escasos" donde algunos de los datos para cualquier uno registro podrían quedar vacíos. El modelo relacional resuelto dividir los datos en una serie de tablas normalizadas (o relaciones), con elementos opcionales que se desplazan fuera de la mesa principal a donde tomarían cuarto sólo si es necesario. Datos pueden libremente insertados, borrados y editados en estas tablas, con el DBMS haciendo lo que sea mantenimiento necesario para presentar una vista de tabla al usuario/aplicación.
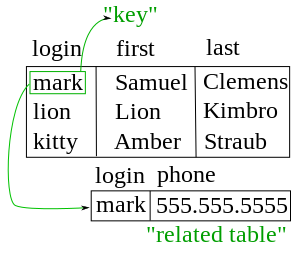
El modelo relacional también permitieron que el contenido de la base de datos para evolucionar sin reescritura constante de enlaces y punteros. La parte relacional proviene de las entidades que hacen referencia a otras entidades en lo que se conoce como relación uno a muchos, como un modelo jerárquico tradicional y una relación muchos-a-muchos, como un modelo de navegación (red). Por lo tanto, un modelo relacional puede expresar modelos jerárquicos y de navegación, así como su modelo tabular nativo, permitiendo para el modelado puro o combinado en términos de estos tres modelos, según lo requiera la aplicación.
Por ejemplo, es un uso común de un sistema de base de datos rastrear información sobre usuarios, su nombre, números de información, diversas direcciones y teléfono de inicio de sesión. En el enfoque de navegación todos estos datos se colocaría en un único registro, y los elementos simplemente no se colocaría en la base de datos. En el enfoque relacional, los datos serían normalizado en una mesa de usuario, una dirección y un teléfono número tabla (por ejemplo). Registros se crearía en estas tablas opcionales sólo si en realidad se proporcionaron los números de teléfono o dirección.
Uniendo la información atrás es la clave de este sistema. En el modelo relacional, un poco de información se utilizó como un "clave", definiendo únicamente un registro concreto. Cuando se recogió información sobre un usuario, la información almacenada en las tablas opcionales se encontraría buscando por esta llave. Por ejemplo, si el nombre de inicio de sesión de un usuario es único, direcciones y números de teléfono para que el usuario se registraría con el nombre de usuario como su clave. Este sencillo "volver a vincular" de relacionados con datos en una sola colección están algo que los lenguajes tradicionales no están diseñados para.
Al igual que el enfoque de navegación requeriría programas con lazo para recoger los registros, el enfoque relacional requeriría bucles para recopilar información acerca de cualquiera uno registro. Solución de Codd para el bucle necesaria era un lenguaje orientado a juego, una sugerencia que más tarde sería desovar el ubicuo SQL. Usando una rama de la matemática conocida como cálculo de tupla, demostró que tal sistema puede apoyar todas las operaciones de bases de datos normales (insertar, actualizar etc.) además de proporcionar un sistema simple para encontrar y devolver establece de los datos en una sola operación.
Papel de Codd fue recogido por dos personas en Berkeley, Eugene Wong y Michael Stonebraker. Empezaron un proyecto conocido como INGRES usando fondos que había ya asignado a un proyecto de base de datos geográfica y estudiantes programadores para producir código. A partir de 1973, INGRES entregó sus primeros productos de prueba que eran generalmente listos para su uso generalizado en 1979. INGRES fue similar al Sistema de R en un número de maneras, incluyendo el uso de un "lenguaje" para acceso a datos, conocida como QUEL. Con el tiempo, INGRES se trasladó al emergente estándar SQL.
IBM hizo una prueba de implementación del modelo relacional, PRTVy a la producción, Sistema de negocio 12, ambos ahora descontinuado. Honeywell escribió MRDS para Multics, y ahora hay dos nuevas implementaciones: Alphora Dataphor y REL. Mayoría de las implementaciones otra DBMS generalmente se llama relacionales son en realidad SQL DBMS.
En 1970, la Universidad de Michigan comenzó el desarrollo de la Sistema de gestión de información MICRO[9] basado en modelo D.L. Childs teoría de conjunto de datos.[10][11][12] Micro fue utilizado para manejar grandes conjuntos de datos por el Departamento de trabajo, la U.S. Environmental Protection Agencye investigadores de la Universidad de Alberta, la Universidad de Michigan, y Wayne State University. Funcionó en computadoras mainframe IBM utilizando el Sistema Terminal de Michigan.[13] El sistema se mantuvo en producción hasta 1998.
Enfoque integrado
En la década de 1970 y 1980 fueron intentos para construir sistemas de base de datos con software y hardware integrado. La filosofía subyacente era que dicha integración proporcionaría un mayor rendimiento a menor costo. Los ejemplos eran IBM Sistema/38, la oferta temprana de Teradatay el Britton Lee, Inc. máquina de base de datos.
Otro enfoque para soporte de hardware para la gestión de base de datos fue ICLes CAF acelerador, un controlador de disco de hardware con capacidades de búsqueda programable. En el largo plazo, estos esfuerzos fracasaron generalmente porque las máquinas especializadas base de datos no podrían mantener el ritmo con el rápido desarrollo y el progreso de computadoras de propósito generales. Así la mayoría de sistemas de base de datos hoy en día son sistemas de software en hardware de propósito general, mediante el almacenamiento de datos informáticos de propósito general. Sin embargo esta idea todavía es perseguida para ciertas aplicaciones por algunas empresas como Netezza y Oracle (Exadata).
Finales de los setenta, DBMS SQL
IBM comenzado a trabajar en un prototipo de sistema basada en los conceptos de Codd Sistema de R en la década de 1970. La primera versión estuvo lista en 1974/5 y trabajar entonces comenzó en mesas múltiples sistemas en los que los datos podrían dividirse para que todos los datos de un registro (algunos de los cuales es opcional) no tuvieron que ser almacenado en un solo gran "trozo". Posteriores versiones multiusuarios fueron probadas por clientes en 1978 y 1979, por ese tiempo un estandarizado lenguaje de consulta – SQL[citación necesitada] – habían sido agregados. Ideas de Codd se establecían como viable y superior a CODASYL, empujando a IBM para desarrollar una versión de producción verdadera del sistema R, conocido como SQL/DSy, posteriormente, Base de datos 2 (DB2).
Larry Ellisonoracle empezó desde una cadena diferente, basada en documentos de IBM sobre sistema R e IBM vencer al mercado cuando la primera versión fue lanzada en 1978.[citación necesitada]
Stonebraker pasó a aplicar las lecciones de INGRES para desarrollar una nueva base de datos Postgres, que ahora se conoce como PostgreSQL. PostgreSQL es de uso frecuente para aplicaciones críticas de la misión mundial (los registros de nombre de dominio .org y .info usan como su principal almacén de datoscomo muchas grandes empresas e instituciones financieras).
En Suecia, papel de Codd también fue leído y Mimer SQL fue desarrollado a partir de mediados de 1970 en Universidad de Uppsala. En 1984, este proyecto se consolidó en una empresa independiente. En la década de 1980, Mimer introdujo transacción manejo de alta robustez en las aplicaciones, una idea que posteriormente se implementó en más otros DBMS.
Otro modelo de datos, la modelo entidad – relación, surgió en 1976 y ganó popularidad por diseño de base de datos como lo destacó una descripción más familiar que el anterior modelo relacional. Más adelante, entidad – relación construcciones fueron adaptadas como un constructo para el modelo relacional de modelado de datos, y la diferencia entre los dos se han convertido en irrelevante.[citación necesitada]
años ochenta, en el escritorio
La década de 1980 marcó el comienzo de la edad de escritorio de computación. Los nuevos ordenadores autorizados sus usuarios con hojas de cálculo como Lotus 1-2-3 y software de base de datos como dBASE. El producto de dBASE era ligero y fácil para cualquier usuario de ordenador de entender fuera de la caja. C. Wayne Ratliff el creador de dBASE declarado: "dBASE era diferente de programas como BASIC, C, FORTRAN y COBOL en que ya se había hecho mucho del trabajo sucio. La manipulación de datos se realiza mediante dBASE en vez de por el usuario, así que el usuario pueda concentrarse en lo que está haciendo, en lugar de tener que meterse con los detalles sucios de apertura, lectura y cierre los archivos y gestionar la asignación de espacio."[14] dBASE fue uno de los títulos de software vendidos en los años ochenta y principios de los noventa.
años ochenta, orientado a objetos
La década de 1980, junto con un aumento de la programación orientada a objetos, vio un crecimiento de cómo se manejaron datos en diversas bases de datos. Los programadores y diseñadores empezaron a tratar los datos en sus bases de datos como objetos. Es decir si los datos de una persona en una base de datos, atributos de esa persona, como su dirección, número de teléfono y edad, eran ahora considerados pertenecen a esa persona en lugar de ser datos extraños. Esto permite que las relaciones entre los datos que las relaciones de objetos y sus atributos y no en los campos individuales.[15] El término"desajuste de impedancia objeto-relacional"describió la molestia de traducir entre objetos programados y tablas de base de datos. Bases de datos objeto y bases de datos objeto-relacionales tratar de resolver este problema proporcionando un lenguaje orientado a objetos (a veces como extensiones a SQL) que los programadores pueden utilizar como alternativa a puramente relacional SQL. En el lado de programación, conocidos como bibliotecas asignaciones de objeto-relacional (ORM) intento de resolver el mismo problema.
2000s, NoSQL y NewSQL
La próxima generación de bases de datos post-relacionales en la década del 2000 llegó a ser conocida como bases de datos NoSQL, incluyendo tiendas de rápido par clave-valor y bases de datos orientada a documentos. Bases de datos XML son un tipo de documento orientado a base de datos estructurada que permite realizar consultas en base XML atributos de documento. Bases de datos XML se utilizan sobre todo en Administración de base de datos para empresas, donde se utiliza como la interoperabilidad de datos de máquina a máquina estándar XML. Bases de datos XML son sobre todo sistemas de software comercial, que incluyen Clusterpoint, MarkLogic y Oracle XML DB.
Bases de datos NoSQL son a menudo muy rápidos, no requieren esquemas de mesa fija, almacenamiento para evitar operaciones de combinación denormalized datos y están diseñan para escala horizontal. Los más populares sistemas NoSQL incluyen MongoDB, Couchbase, Riak, Memcached, Redis, CouchDB, Hazelcast, Apache Cassandra y HBase,[16] ¿Cuáles son todos software de código abierto productos.
En los últimos años hubo una alta demanda de bases de datos distribuidas masivamente con tolerancia alta división pero según el Teorema del CAP es imposible para un sistema distribuido al mismo tiempo proporcionar consistencia, garantiza la disponibilidad y partición de la tolerancia. Un sistema distribuido puede satisfacer cualquiera de las dos de estas garantías al mismo tiempo, pero no a los tres. Por esa razón muchas bases de datos NoSQL utilizan lo que se llama consistencia eventual para proporcionar la disponibilidad y tolerancia de partición garantiza con un reducido nivel de consistencia de los datos.
NewSQL es una clase de modernas bases de datos relacionales que pretende ofrecer el mismo rendimiento escalable de sistemas NoSQL para transacciones en línea (leer-escribir) las cargas de trabajo de procesamiento mientras sigue usando SQL y mantener las garantías de un sistema de base de datos tradicionales ácidas. Estas bases de datos incluyen ScaleBase, Clustrix, EnterpriseDB, MemSQL, NuoDB[17] y VoltDB.
Investigación
La tecnología de base de datos ha sido un tema de investigación activa desde los años sesenta, tanto en Academia y en los grupos de investigación y desarrollo de empresas (por ejemplo IBM Research). Actividad de investigación incluye teoría y desarrollo de prototipos. Temas de investigación notable han incluido modelos, el concepto de transacción atómica y afines control de concurrencia técnicas, lenguajes de consulta y optimización de consultas métodos, RAIDy mucho más.
El área de investigación de base de datos tiene varias dedicada revistas académicas (por ejemplo, ACM Transactions on Database Systems-TODS, Ingeniería del conocimiento y datos-DKE) y anual conferencias (por ejemplo, ACM SIGMOD, ACM VAINAS, VLDB, IEEE ICDE).
Ejemplos
Una manera de clasificar las bases de datos implica al tipo de su contenido, por ejemplo: bibliográficos, objetos de texto del documento, estadística, o multimedia. Otra forma es mediante su área de aplicación, por ejemplo: contabilidad, composiciones musicales, películas, banca, manufactura o seguros. Una tercera manera es por algún aspecto técnico, como el tipo de estructura o interfaz de base de datos. Esta sección enumera algunos de los adjetivos utilizados para caracterizar diferentes tipos de bases de datos.
- Un base de datos en memoria es una base de datos que reside principalmente en memoria principal, pero es típicamente respaldada por almacenamiento de datos de computadora no volátil. Bases de datos de la memoria principal son más rápidas que las bases de datos de disco y tan a menudo se utilizan en tiempo de respuesta es crítica, como en equipos de red de telecomunicaciones.[18]SAP HANA la plataforma es un tema muy candente para bases de datos en memoria. De mayo de 2012, HANA era capaz de ejecutar en servidores con memoria principal 100TB desarrollada por IBM. El cofundador de la compañía afirmó que el sistema era suficientemente grande como para correr a los clientes SAP más grandes 8.
- Un base de datos activa incluye una arquitectura orientada a eventos que puede responder a condiciones tanto dentro como fuera de la base de datos. Posibles usos incluyen la supervisión de la seguridad, las alertas, recopilación de las estadísticas y autorización. Muchas bases de datos proporcionan funciones de base de datos activa en forma de factores desencadenantes de la base de datos.
- A base de datos de nube se basa en tecnología Cloud. Tanto la base de datos y la mayoría de su DBMS reside remotamente, "en la nube", mientras que sus aplicaciones son tanto desarrollados por programadores y después mantenidos y utilizados por los usuarios finales (de la aplicación) a través de un navegador web y APIs abiertas.
- Almacenes de datos archivo de datos de bases de datos operacionales y a menudo de fuentes externas tales como empresas de investigación de mercado. El almacén se convierte en la fuente central de datos para su uso por los gerentes y otros usuarios finales que no tengan acceso a los datos operacionales. Por ejemplo, datos de ventas podrían ser agregadas a los totales semanales y convertidas a partir de códigos de producto interno para usar UPCs Así pueden ser comparados con ACNielsen datos. Algunos componentes básicos y esenciales de almacenamiento de datos incluyen recuperar, analizar, y minería datos, transformación, carga y administración de datos con el fin de que estén disponibles para su uso posterior.
- A base de datos deductiva combina programación de la lógica con una base de datos relacional, por ejemplo mediante la Datalog idioma.
- A base de datos distribuida es uno en el que el DBMS y los datos abarcan varios ordenadores.
- Una base de datos orientada al documento está diseñado para almacenar, recuperar y gestión orientada al documento o información semi estructurada. Documento orientado a bases de datos son una de las principales categorías de bases de datos NoSQL.
- Un base de datos incorporada el sistema es un DBMS que está estrechamente integrado con un software de aplicación que requiere acceso a los datos almacenados de tal manera que el DBMS está oculto para los usuarios finales de la aplicación y requiere poco o ningún mantenimiento en curso.[19]
- Bases de datos del usuario final constan de datos desarrollados por los usuarios finales individuales. Ejemplos de estos son colecciones de documentos, hojas de cálculo, presentaciones multimedias y otros archivos. Existen varios productos para apoyar a esas bases de datos. Algunos de ellos son mucho más simples que DBMS pleno derecho, con la funcionalidad de DBMS más elemental.
- A sistema de bases de datos federadas se compone de varias bases de distintos, cada uno con su propio DBMS. Es manejado como una sola base de datos por un sistema de gestión de bases de datos federadas (FDBMS), que integra transparentemente múltiples DBMSs autónomas, posiblemente de distintos tipos (en cuyo caso sería también un sistema de base de datos heterogéneos) y les proporciona una visión conceptual integrada.
- A veces el término múltiples bases de datos se utiliza como sinónimo de base de datos federada, aunque puede referirse a un grupo menos integrado (por ejemplo, sin un FDBMS y un esquema integrado administrado) de bases de datos que cooperan en una sola aplicación. En este caso, normalmente middleware se utiliza para la distribución, que normalmente incluye un commit atómico de (ACP), por ejemplo, la Protocolo de dos fases, para permitir transacciones distribuidas (globales) a través de las bases de datos participantes.
- A base de datos de gráfico es una especie de base de datos NoSQL que utiliza estructuras de gráfico con los nodos, bordes y propiedades para representar y almacenar información. Bases de datos gráfico general que pueden almacenar cualquier gráfico son distintas de las bases de datos especializadas gráfico tales como triplestores y bases de datos de red.
- Un matriz de DBMS es una especie de NoSQL DBMS que permite modelar, almacenar y recuperar (generalmente grande) multidimensional arreglos de discos como imágenes de satélite y salida de la simulación del clima.
- En un hipertexto o hipermedia base de datos, cualquier palabra o un fragmento de texto que representa un objeto, por ejemplo, otro pedazo de texto, un artículo, una foto o una película, puede ser hipervínculos a dicho objeto. Bases de datos de hipertexto son particularmente útiles para la organización de grandes cantidades de información dispar. Por ejemplo, son útiles para la organización enciclopedias en línea, donde los usuarios pueden saltar convenientemente alrededor del texto. El World Wide Web por lo tanto es una base de datos grande hipertexto distribuido.
- A base de conocimientos (abreviado KB, kb o Δ[20][21]) es un tipo especial de base de datos para gestión del conocimiento, proporcionando los medios para la colección automatizada, organización, y recuperación de conocimiento. También una colección de datos que representan problemas con sus soluciones y experiencias relacionadas.
- A base de datos móvil puede ser llevado o sincronizado desde un dispositivo de computación móvil.
- Bases de datos operacionales almacenar datos detallados sobre las operaciones de una organización. Típicamente procesan volúmenes relativamente altos de cambios usando transacciones. Los ejemplos incluyen bases de datos del cliente ese contacto de registros, el crédito e información demográfica sobre los clientes de negocio, bases de datos personal que contienen la información tales como salario, beneficios, datos de habilidades de los empleados, planificación de recursos empresariales los sistemas que registran información sobre los componentes del producto, inventario de partes y bases de datos financieros que seguir la pista de dinero de la organización, asuntos contables y financieros.
- A base de datos paralela pretende mejorar el rendimiento a través de paralelización para tareas como la carga de datos, índices de construcción y evaluación de las consultas.
-
-
Las principales arquitecturas paralelas de DBMS que son inducidas por el subyacente hardware arquitectura son:
- Arquitectura de memoria compartida, donde varios procesadores comparten el espacio de la memoria principal, así como otro almacenamiento de datos.
- Arquitectura de disco compartido, donde cada unidad de procesamiento (típicamente consiste de múltiples procesadores) tiene su propia memoria principal, pero todas las unidades de compartan el almacenamiento de otro.
- Nada compartido arquitectura, donde cada unidad de proceso tiene su propia memoria principal y el otro almacenaje.
-
Las principales arquitecturas paralelas de DBMS que son inducidas por el subyacente hardware arquitectura son:
- Bases de datos probabilísticos emplear lógica difusa extraer inferencias de datos imprecisos.
- Bases de datos en tiempo real procesar transacciones lo suficientemente rápidas como para que el resultado que se actúe de inmediato.
- A base de datos espacial puede almacenar los datos con las características multidimensionales. Las consultas sobre tales datos incluyen consultas de localización basada, como "Dónde está el hotel más cercano en mi área?".
- A base de datos temporal tiene aspectos de tiempo incorporado, por ejemplo, un modelo de datos temporales y una versión temporal de SQL. Más específicamente los aspectos temporales incluyen generalmente válido-tiempo y transacción.
- A base de datos orientada a la terminología se basa en un base de datos orientada a objetos, a menudo personalizado para un campo específico.
- Un datos no estructurados base de datos está diseñado para almacenar en un diversos objetos manejables y protegida de manera que no se ajustan naturalmente y convenientemente en común las bases de datos. Puede incluir mensajes de correo electrónico, documentos, revistas, objetos multimedia, etc.. El nombre puede ser confuso ya que algunos objetos pueden ser altamente estructurados. Sin embargo, la colección de todo posible objeto no encaja en un marco estructurado predefinido. La mayoría estableció DBMSs ahora admiten los datos no estructurados en varias formas, y nuevo dedicado DBMS están surgiendo.
Diseño y modelado
La primera tarea de un diseñador de base de datos es producir una modelo de datos conceptual Eso refleja la estructura de la información que se celebrará en la base de datos. Un enfoque común para esto es desarrollar un modelo entidad-relación, a menudo con la ayuda de herramientas de dibujo. Otro método popular es el Unified Modeling Language. Un modelo de datos exitoso reflejará fielmente el estado posible del mundo exterior siendo modelado: por ejemplo, si la gente puede tener más de un número de teléfono, permitirá esta información ser capturado. Diseño de un modelo de datos conceptual requiere una buena comprensión del dominio de aplicación; típicamente involucra profundas preguntas sobre las cosas de interés para una organización, como "un cliente también puede ser un proveedor?", o "Si un producto se vende con dos diferentes formas de empaque, son el mismo producto o productos diferentes?", o "Si un avión vuela desde Nueva York a Dubai vía Frankfurt, es ese uno vuelo o dos (o incluso tres)?". Las respuestas a estas preguntas establecen las definiciones de la terminología utilizada por entidades (clientes, productos, vuelos, segmentos de vuelo) y sus atributos y relaciones.
Produciendo el modelo de datos conceptual a veces implica la entrada de procesos de negocio, o el análisis de flujo de trabajo en la organización. Esto puede ayudar a establecer qué información es necesaria en la base de datos, y lo que puede quedar fuera. Por ejemplo, puede ayudar a decidir si la base de datos debe mantener datos históricos, así como los datos actuales.
Producir un modelo conceptual de datos que los usuarios están contentos con, la próxima etapa es traducir esto en una esquema que implementa las estructuras de datos relevantes dentro de la base de datos. Este proceso se denomina diseño lógico de bases de datos, y el resultado es un modelo de datos lógicos expresado en forma de un esquema. Considerando que el modelo de datos conceptual (en teoría al menos) independientemente de la elección de la tecnología de base de datos, el modelo de datos lógicos se expresará en términos de un modelo de base de datos particular soportado por los elegidos DBMS. (Los términos modelo de datos y modelo de base de datos a menudo se utilizan indistintamente, pero en este artículo que utilizamos modelo de datos para el diseño de una base de datos específica, y modelo de base de datos para la notación modela utilizada para expresar ese diseño.)
El modelo más popular de la base de datos para bases de datos de propósito generales es el modelo relacional, o más precisamente, el modelo relacional, representado por el lenguaje SQL. El proceso de creación de un diseño lógico de bases de datos usando este modelo utiliza un enfoque metódico conocido como Normalización. El objetivo de la normalización es asegurar que cada escuela primaria "hecho" sólo se registra en un solo lugar, de modo que las inserciones, actualizaciones y eliminaciones automáticamente mantienen la consistencia.
La etapa final de diseño de base de datos es tomar las decisiones que afectan el rendimiento, escalabilidad, recuperación, seguridad y similares. Esto se denomina diseño de base de datos física. Un objetivo clave en esta etapa es independencia de datos, lo que significa que las decisiones tomadas para fines de optimización de rendimiento deben ser invisibles a los usuarios finales y aplicaciones. Diseño físico es impulsada principalmente por los requerimientos de performance y requiere un buen conocimiento de la carga de trabajo esperado y patrones de acceso y un profundo conocimiento de las características ofrecidas por los elegidos DBMS.
Otro aspecto del diseño físico de base de datos es la seguridad. Se trata de definir ambos control de acceso para objetos de base de datos así como definir los niveles de seguridad y métodos de los datos de sí mismo.
Modelos
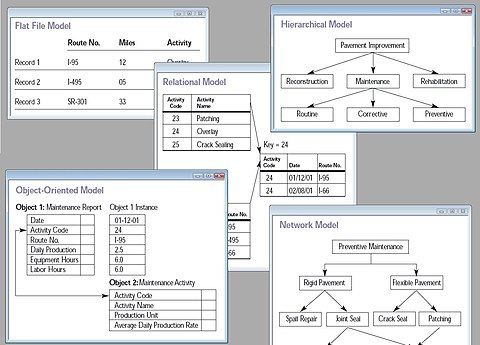
Un modelo de base de datos es un tipo de modelo de datos que determina la estructura lógica de una base de datos y fundamentalmente determina de qué manera datos puede ser almacenado, organizadas y manipuladas. El ejemplo más popular de un modelo de base de datos es el modelo relacional (o la aproximación de SQL de relacional), que utiliza un formato basado en la tabla.
Modelos de datos lógicos comunes para bases de datos incluyen:
- Modelo de base de datos jerárquica
- Modelo de red
- Modelo relacional
- Modelo entidad – relación
- Modelo entidad – relación mejorada
- Modelo de objetos
- Modelo de documento
- Modelo – entidad – valor de atributo
- Esquema en estrella
Una base de datos objeto-relacional combina las dos estructuras relacionadas.
Modelos de datos físicos incluyen:
- Índice invertido
- Archivo plano
Otros modelos incluyen:
- Modelo asociativo
- Modelo multidimensional
- Modelo de matriz
- Modelo multivalorado
- Modelo semántico
- Base de datos XML
Vistas internas, conceptuales y externos

Un sistema de gestión de base de datos proporciona tres vistas de los datos de base de datos:
- El nivel externo define como ve a la organización de datos en la base de cada grupo de usuarios finales. Una única base de datos puede tener cualquier número de puntos de vista a nivel externo.
- El nivel conceptual unifica las diversas opiniones externas a una visión global compatible.[23] Proporciona la síntesis de todas las vistas externas. Se está fuera del alcance de los usuarios de bases de datos diferentes y es algo de interés para los desarrolladores de aplicaciones de bases de datos y administradores de bases de datos.
- El nivel interno (o nivel físico) es la organización interna de los datos dentro de un DBMS (vea la sección de ejecución más abajo). Se refiere a costo, rendimiento, escalabilidad y otras cuestiones operativas. Se trata de diseño del almacenamiento de los datos, utilizando como estructuras de almacenamiento índices para mejorar el rendimiento. De vez en cuando almacena datos de vistas individuales (vistas materializadas), calculado a partir de datos genéricos, si rendimiento justificación para tal redundancia. Se balancea requisitos de desempeño de todas las vistas externas, posiblemente conflictivas, en un intento de optimizar el rendimiento general en todas las actividades.
Mientras que normalmente sólo hay uno conceptual (o lógica) y física (o interna) vista de los datos, puede haber cualquier número de diferentes puntos de vista externos. Esto permite a los usuarios ver la información de base de datos de una manera más relacionados con el negocio en lugar de un punto de vista técnico, procesamiento. Por ejemplo, un departamento financiero de una empresa necesita los detalles del pago de todos los empleados como parte de los gastos de la empresa, pero no necesita detalles sobre los empleados que son los intereses de la recursos humanos Departamento. Por lo tanto diferentes departamentos necesitan diferentes Vistas de base de datos de la empresa.
La arquitectura de tres niveles de base de datos se relaciona con el concepto de independencia de datos que fue uno de los principales impulsores iniciales del modelo relacional. La idea es que los cambios realizados en un determinado nivel no afectan la vista a un nivel superior. Por ejemplo, cambios en el ámbito interno no afectan a los programas de aplicaciones escritos utilizando interfaces a nivel conceptuales, que reduce el impacto de cambios físicos para mejorar el rendimiento.
El punto de vista conceptual proporciona un nivel de indirección entre internos y externos. Por un lado proporciona una vista común de la base de datos, independiente de las estructuras diferentes vista externa, y por otro lado abstrae lejos detalles de cómo los datos se almacenan o gestionados (nivel interno). En principio todos los niveles y cada vista externa, pueden presentarse por un modelo de datos diferentes. En la práctica generalmente un DBMS dado utiliza el mismo modelo de datos para los niveles conceptuales (por ejemplo, el modelo relacional) y la externa. El nivel interno, que está escondido dentro del DBMS y depende de su implementación (ver sección de implementación más abajo), requiere un nivel de detalle y utiliza sus propios tipos de estructura de tipos de datos.
Separar el externos, conceptual y interno los niveles fueron una de las características principales de las implementaciones de modelo de base de datos relacional que dominan las bases de datos del siglo XXI.[23]
Idiomas
Lenguas de base de datos son especiales, que hacen uno o más de las siguientes:
- Lenguaje de definición de datos – define los tipos de datos y las relaciones entre ellos
- Lenguaje de manipulación de datos – realiza tareas como insertar, actualizar o eliminar las ocurrencias de datos
- Lenguaje de consulta – permite buscar información y computación derivaron información
Idiomas de base de datos son específicos de un modelo de datos particulares. Los ejemplos notables incluyen:
- SQL combina las funciones de definición de datos, manipulación de datos y consulta en un solo idioma. Fue uno de los primeros idiomas comerciales para el modelo relacional, aunque sale en algunos aspectos del el modelo relacional según lo descrito por Codd (por ejemplo, las filas y columnas de una tabla pueden ser ordenadas). SQL se convirtió en un estándar de la American National Standards Institute (ANSI) en 1986 y de la International Organization for Standardization (ISO) en 1987. Las normas han sido mejoradas con regularidad desde y es apoyado por todos DBMS relacional comercial convencional (con distintos grados de conformidad).[24][25]
- OQL es un lenguaje de modelo de objetos estándar (de la Datos de Object Management Group). Ha influenciado el diseño de algunos de los nuevos lenguajes de consulta como JDOQL y EJB QL.
- XQuery es un lenguaje de consulta XML estándar implementado por los sistemas de base de datos XML como MarkLogic y Existen, por bases de datos relacionales con capacidad de XML como Oracle y DB2 y también por los procesadores XML en memoria como Saxon.
- SQL/XML combina XQuery con SQL.[26]
Un lenguaje de base de datos también puede incorporar características como:
- DBMS específica configuración y almacenamiento de información de gestión del motor
- Los cómputos para modificar los resultados de la consulta, como contar, suma, promedio, clasificación, agrupación y referencias cruzadas
- Aplicación de restricciones (por ejemplo, en una base de datos automotora, permitiendo sólo un tipo de motor por coche)
- Aplicación versión de interfaz de programación del lenguaje de consulta, para conveniencia del programador
Rendimiento, seguridad y disponibilidad
Debido a la importancia crítica de la tecnología de base de datos para el buen funcionamiento de una empresa, los sistemas de bases de datos incluyen complejos mecanismos para proporcionar el rendimiento requerido, seguridad y disponibilidad y permiten a los administradores de bases de datos controlar el uso de estas características.
Almacenamiento de información
Almacenamiento de base de datos es el contenedor de la materialización física de una base de datos. Se compone de la interno (físico) nivel en la arquitectura de base de datos. También contiene toda la información necesaria (por ejemplo, metadatos, "los datos sobre los datos" e interno estructuras de datos) para reconstruir la nivel conceptual y nivel externo a nivel interno cuando sea necesario. Poner datos en almacenamiento permanente es generalmente la responsabilidad de la motor de base de datos también conocido como "motor de almacenamiento". Aunque normalmente se accede por un DBMS a través del sistema operativo subyacente (y a menudo utilizan los sistemas operativos sistemas de archivos como intermediarios para el diseño del almacenamiento), propiedades de almacenamiento de configuración son extremadamente importantes para el funcionamiento eficiente del DBMS y así estrechamente son mantenidos por los administradores de bases de datos. Un DBMS, mientras está en funcionamiento, siempre tiene su base de datos que residen en varios tipos de almacenamiento (por ejemplo, memoria y almacenamiento externo). Los datos de base de datos y la información adicional necesaria, posiblemente en cantidades muy grandes, se cifran en pedacitos. Datos residen normalmente en el almacenamiento de información en estructuras que parecen completamente diferente de la apariencia de los datos en los niveles conceptuales y externos, pero en formas que intentan optimizar (la mejor posible) reconstrucción de estos niveles cuando sea necesario por los usuarios y programas, así como para la informática tipos adicionales de información de los datos necesaria (por ejemplo, al consultar la base de datos).
Apoyo DBMSs especificando que codificación de caracteres fue utilizado para almacenar los datos, así las codificaciones múltiples pueden ser utilizadas en la misma base de datos.
Bajo nivel de varios estructuras de almacenamiento de base de datos son utilizados por el motor de almacenamiento para serializar el modelo de datos para que se puede escribir en el medio de la elección. Pueden utilizarse técnicas como la indexación para mejorar el rendimiento. Almacenamiento convencional está orientada a filas, pero también hay orientación de columna y bases de datos de correlación.
Vistas materializadas
Redundancia de almacenamiento a menudo se emplea para aumentar el rendimiento. Un ejemplo común es almacenar vistas materializadas, que consisten en con frecuencia necesario vistas externas o resultados de la consulta. Almacenar tales opiniones ahorra la computación caro de ellos cada vez que se necesitan. Las desventajas de vistas materializadas son los gastos indirectos incurridos durante la actualización para mantenerlos sincronizados con sus datos originales de la base de datos actualizada y el costo del despido de almacenamiento.
Replicación
De vez en cuando una base de datos emplea redundancia de almacenamiento de replicación de objetos de base de datos (con uno o más ejemplares) para aumentar la disponibilidad de los datos (tanto para mejorar el rendimiento de simultánea múltiples accesos de usuarios finales a un mismo objeto de base de datos y para proporcionar flexibilidad en caso de fracaso parcial de una base de datos distribuida). Las actualizaciones de un objeto replicado necesitan ser sincronizado a través de las copias del objeto. En muchos casos la base de datos se replica.
Seguridad
|
|
El siguiente texto tiene que ser armonizado con texto en Seguridad de base de datos. |
Seguridad de base de datos aborda todos los aspectos diversos de proteger el contenido de la base de datos, sus propietarios y sus usuarios. Se extiende desde protección contra usos intencionales de bases de datos no autorizada a accesos involuntarios de base de datos por entidades no autorizadas (por ejemplo, una persona o un programa de computadora).
Control de acceso de base de datos se ocupa de controlar que (una persona o un determinado programa informático) puede acceder a información en la base de datos. La información puede abarcar objetos de base de datos específica (por ejemplo, los tipos de registro, registros específicos, estructuras de datos), ciertos cálculos sobre ciertos objetos (por ejemplo, tipos de consultas o preguntas específicas), o utilizando las rutas de acceso específico al anterior (por ejemplo, mediante índices específicos u otras estructuras de datos, acceso a la información). Controles de acceso de base de datos se establecen por personal autorizado (por el propietario de la base de datos) especial que utiliza dedicado protegido interfaces de seguridad DBMS.
Esto puede gestionarse directamente en forma individual, o por la asignación de los individuos y privilegios para grupos, o (en los modelos más elaborados) mediante la asignación de los individuos y grupos para papeles que luego se conceden derechos. Seguridad de datos impide que los usuarios no autorizados ver o actualizar la base de datos. Uso de contraseñas, los usuarios pueden acceder a la base de datos completa o subconjuntos del llamado "subschemas". Por ejemplo, una base de datos del empleado puede contener todos los datos de un empleado individual, pero un grupo de usuarios puede ser autorizado a ver sólo la información de la nómina, mientras que otros se permitieron el acceso al trabajo sólo historia y datos médicos. Si el DBMS proporciona una manera de entrar en forma interactiva y actualizar la base de datos, así como interrogarlo, esta capacidad permite gestionar bases de datos personales.
Seguridad de datos en general se ocupa de proteger determinados trozos de datos, tanto físicamente (es decir, de la corrupción, destrucción o eliminación; por ejemplo, véase seguridad física), o la interpretación de ellos, o partes de ellas a información significativa (por ejemplo, por mirar las cadenas de bits que comprenden, concluyendo números específicos de tarjeta de crédito válidas; por ejemplo, véase cifrado de datos).
Cambio y acceder a los registros la tala que acceder a los atributos, lo que cambió, y cuando se cambió. Registro de servicios permiten un forense auditoría de base de datos después de mantener un registro de sucesos de acceso y cambios. Código de nivel de aplicación a veces se utiliza para registrar los cambios en lugar de dejar que esto a la base de datos. Monitoreo se puede configurar para intentar detectar las brechas de seguridad.
Transacciones y concurrencia
Transacciones de bases de datos puede utilizarse para introducir algún nivel de tolerancia a fallos y integridad de datos después de la recuperación de un accidente. Una transacción de base de datos es una unidad de trabajo, encapsulando típicamente un número de operaciones sobre una base de datos (por ejemplo, leyendo un objeto de base de datos, escritura, adquiriendo cerraduraetc.), una abstracción apoyada en bases de datos y también otros sistemas. Cada transacción ha definido límites en cuanto a qué código de programa/ejecuciones están incluidas en la transacción (determinada por el programador de la transacción a través de los comandos especiales de la transacción).
El acrónimo ÁCIDO se describen algunas propiedades ideales de una transacción de base de datos: Atomicidad, Consistencia, Aislamiento, y Durabilidad.
Migración
- Véase también la sección Migración de bases de datos en el artículo Migración de datos
Una base de datos construida con un DBMS no es trasladable a otros DBMS (es decir, los otro DBMS no ejecutarlo). Sin embargo, en algunas situaciones es deseable para moverse, migrar una base de datos desde un DBMS a otra. Las razones son principalmente económicas (DBMSs diferentes pueden tener diferentes costos totales de propiedad o TCOs), funcional y operativa (DBMSs diferentes pueden tener diferentes capacidades). La migración implica la transformación de la base de datos desde un tipo de DBMS a otro. La transformación debe mantener (si es posible) la base de datos relacionados con la aplicación (es decir, todo lo relacionado con programas de aplicación) intacto. Así, los niveles arquitectura conceptual y externo de la base de datos deben mantenerse en la transformación. Sería deseable que también se mantienen algunos aspectos del nivel de arquitectura interna. Una migración de bases de datos complejas o grandes puede ser un proyecto complicado y costoso (una vez) por sí mismo, lo que debe tenerse en la decisión de migrar. Esta a pesar del hecho de que existan herramientas para ayudar a la migración entre bases de datos específicas. típicamente un vendedor DBMS proporciona herramientas para ayudar a importar bases de datos de otras bases de datos populares.
Construcción, mantenimiento y ajuste
Después de diseñar una base de datos para una aplicación, el siguiente paso es construir la base de datos. Típicamente un apropiado DBMS para fines generales puede ser seleccionado para ser utilizados para este propósito. Un DBMS proporciona la necesaria interfaces de usuario para ser utilizados por los administradores de bases de datos para definir las estructuras de datos de la aplicación necesaria dentro de modelo de datos respectivos de los DBMS. Otras interfaces de usuario se utilizan para seleccionar los parámetros necesarios de DBMS (como relacionados con la seguridad, los parámetros de asignación de almacenamiento de información, etc..).
Cuando esté lista la base de datos (se definen todas las estructuras de datos y otros componentes necesarios) normalmente está poblado con datos de la aplicación inicial (inicialización de la base de datos, que es típicamente un proyecto distinto, en muchos casos especializados DBMS utilizando interfaces que apoyo a granel la inserción) antes de hacerlo operacional. En algunos casos se convierte en la base de datos operacional mientras vacíen de datos de aplicaciones y datos se acumularon durante su funcionamiento.
Una vez creada la base de datos, reinicializará y poblado debe mantenerse. Diversos parámetros de base de datos pueden necesitar cambiar y la base de datos puede necesitar ser afinado)Tuning) para un mejor rendimiento; las estructuras de datos de la aplicación pueden ser cambiadas o agregados, nueva aplicación relacionados con programas pueden escribirse para agregar funcionalidad de la aplicación, etc..
Backup y restore
A veces se desea devolver una base de datos a un estado anterior (por muchas razones, por ejemplo, los casos cuando la base de datos se encuentra dañado debido a un error de software, o si se ha actualizado con datos erróneos). Para lograr esto un copia de seguridad la operación se realiza ocasionalmente o continuamente, donde cada uno el deseado estado de base de datos (es decir, los valores de sus datos y su integración en las estructuras de datos de base de datos) se mantiene dentro de archivos de backup dedicados (existen muchas técnicas para hacerlo de manera eficaz). Cuando este estado es necesaria, es decir, cuando se decide por un administrador de base de datos para devolver la base de datos a este estado (por ejemplo, especificando este estado por un punto deseado en el momento en que era la base de datos en este estado), estos archivos se utilizan para restaurar ese estado.
Otros
Otras características DBMS podrían incluir:
- Registros de base de datos
- Componente de gráficos para la producción de gráficos y tablas, especialmente en un sistema de almacén de datos
- Optimizador de consultas – Realiza optimización de consultas en cada consulta a elegir para los más eficientes plan de consulta (un orden parcial (árbol) de operaciones) a ser ejecutado para calcular el resultado de la consulta. Pueden ser específicas de un motor de almacenamiento particulares.
- Herramientas o ganchos para diseño de bases de datos, programación de aplicaciones, mantenimiento del programa de aplicación, análisis de performance de la base de datos y monitoreo, configuración de base de datos de monitoreo, configuración de hardware DBMS (una base de datos relacionado y DBMS pueden abarcar computadoras, redes y unidades de almacenamiento) y relacionados con la cartografía de base de datos (especialmente para un DBMS distribuido), asignación de almacenamiento de información y diseño de base de datos de monitoreo, migración de almacenamiento, etc..
Véase también
|
- Comparación de herramientas de base de datos
- Comparación de sistemas de gestión de base de datos de objeto
- Comparación de sistemas de gestión de base de datos objeto-relacional
- Comparación de sistemas de gestión de base de datos relacional
- Jerarquía de datos
- Base de datos de prueba
- Arquitectura centrada en la base de datos
- Conjunto de datos orientada a pregunta
Referencias
- ^ Jeffrey Ullman 1997: Primer curso en sistemas de base de datos, Prentice-Hall Inc., Simon & Schuster, Página 1, ISBN 0-13-861337-0.
- ^ Tsitchizris, D. C. y f el. H. Lochovsky (1982). Modelos de datos. Acantilados de Englewood, Prentice-Hall.
- ^ Beynon-Davies P. (2004). Sistemas de base de datos 3ª edición. Palgrave, Basingstoke, Reino Unido. ISBN 1-4039-1601-2
- ^ Raul, Michael Dang, Dwaine R. Snow, Xiaomei Wang (03 de julio de 2008). "Introducción a DB2". 17 de marzo de 2013.. Este artículo cita a un tiempo de desarrollo de 5 años con 750 personas para lanzamiento de DB2 9 solo
- ^ C. W. Bachmann (noviembre de 1973), El programador como navegante, MCCA (Premio Turing Conferencia 1973)
- ^ "base de datos, n". OED en línea. Oxford University Press. Junio de 2013. 12 de julio de 2013.
- ^ IBM Corporation. "IBM información de administración de sistema (IMS) 13 transacción y servidores de base de datos ofrece alto rendimiento y bajo coste total de propiedad". 20 de febrero de 2014.
- ^ Codd, E.F. (1970)."Un modelo relacional de datos para grandes bancos de datos compartidos". En: Communications of the ACM 13 (6): 377-387.
- ^ William Hershey y Carol Easthope, "Un set data teórica estructura y recuperación de lenguaje", Conferencia de informática común, mayo de 1972 en la primavera ACM SIGIR Forum, Volumen 7, número 4 (diciembre de 1972), págs. 45 – 55, DOI =10.1145/1095495.1095500
- ^ Ken norte, "Sistemas, modelos de datos y la independencia de datos", Del Dr. Dobb's, 10 de marzo de 2010
- ^ Descripción de la estructura de una teoría de conjunto de datos, D. L. Childs, 1968, informe técnico 3 de la CONCOMP (investigación en uso conversacional de computadoras) proyecto, University of Michigan, Ann Arbor, Michigan, EEUU
- ^ Viabilidad de una estructura de datos Set-teórico: una estructura General basada en una definición reconstituida de relación, D. L. Childs, 1968, informe técnico 6 de la CONCOMP (investigación en uso conversacional de computadoras) proyecto, University of Michigan, Ann Arbor, Michigan, EEUU
- ^ Información MICRO Management System (versión 5.0) Reference Manual, M.A. Kahn, D.L. Rumelhart y B.L. Bronson, octubre de 1977, Instituto de trabajo y relaciones laborales (ILIR), Universidad de Michigan y la Universidad Estatal Wayne
- ^ Entrevista con Wayne Ratliff. La historia de FoxPro. Recuperado encendido 2013-07-12.
- ^ Desarrollo de un DBMS orientado a objetos; Portland, Oregon, Estados Unidos; Páginas: 472-482; 1986; ISBN 0-89791-204-7
- ^ "DB-motores Ranking". De enero de 2013. 22 de enero de 2013.
- ^ Proctor, Seth (2013). "Explorar la arquitectura de la base de datos NuoDB, parte 1". 2013-07-12.
- ^ "Telecomunicaciones sistemas de señales para arriba como un revendedor de TimesTen; Los transportistas y operadores de telefonía móviles ganan plataforma en tiempo real para los servicios basados en localización". Business Wire. 24 / 06 / 2002.
- ^ Graves, Steve. "Cunas bases de datos para sistemas empotrados", Embedded Computing Design revista, enero de 2007. Recuperado encendido 13 de agosto de 2008.
- ^ Argumentación en Inteligencia Artificial por Iyad Rahwan, Guillermo R. Simari
- ^ "OWL DL semántica". 10 de diciembre de 2010.
- ^ ITL.NIST.gov (1993) Definición de integración de información de modelado (IDEFIX). 21 de diciembre de 1993.
- ^ a b Fecha de 1990, págs. 31 – 32
- ^ Chapple, Mike. "Fundamentos SQL". Bases de datos. About.com. 2009-01-28.
- ^ "Estructurada Query Language (SQL)". International Business Machines. 27 de octubre de 2006. de 2007-06-10.
- ^ Wagner, Michael (2010), "1. Auflage", SQL / estándar – Evaluierung der Standardkonformität ausgewählter Datenbanksysteme, Diplomica Verlag, ISBN3-8366-9609-6
Lectura adicional
- Ling Liu y Tamer M. Özsu (eds.) (2009). "Enciclopedia de los sistemas de bases de datos, Ilustración 4100 60 p. ISBN 978-0-387-49616-0.
- Beynon-Davies, P. (2004). Sistemas de base de datos. 3ª edición. Palgrave, Houndmills, Basingstoke.
- Connolly, Thomas y Carolyn Begg. Sistemas de base de datos. Nueva York: Harlow, 2002.
- Fecha, J. C. (2003). Una introducción a los sistemas de bases de datos, quinta edición. Addison Wesley. ISBN0-201-51381-1.
- Gray, J. y Reuter, A. Procesamiento de transacciones: Conceptos y técnicas, 1ª edición, Morgan Kaufmann Publishers, 1992.
- Kroenke, David M. y David J. Auer. Conceptos de base de datos. 3ª ed. Nueva York: Prentice, 2007.
- Raghu Ramakrishnan y Johannes Gehrke, Sistemas de gestión de base de datos
- Abraham Silberschatz, Henry F. Korth, S. Sudarshan, Conceptos de sistemas de bases de datos
- Discusión sobre los sistemas de bases de datos, [1]
- Lightstone, S.; Teorey, T.; Nadeau, T. (2007). Diseño físico de la base de datos: Guía de los profesionales de base de datos a la explotación de los índices, vistas, almacenamiento y mucho más. Morgan Kaufmann prensa. ISBN0-12-369389-6.
- Teorey, T.; Lightstone, S. y Nadeau, T. Modelado y diseño de bases de datos: diseño lógico, 4ª edición, Morgan Kaufmann Press, 2005. ISBN 0-12-685352-5
Enlaces externos
| Encontrar más información sobre Base de datos en Copro hermana proyectos | |
| Definiciones de Wikcionario | |
| Los medios de comunicación de Commons | |
| Citas de Wikiquote | |
| Textos originales de Wikisource | |
| Libros de texto de Wikilibros | |
| Recursos de aprendizaje de Wikiversidad | |
- Base de datos en DMOZ
- Extensión de archivo DB – informaciones acerca de los archivos con extensión DB
|
||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||
|
||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||