Linaje de datos para sistemas de datos grandes
"Linaje de datos se define como un ciclo de vida de datos que incluye el origen de los datos y donde se mueve con el tiempo. " [1] Describe lo que sucede a los datos mientras pasa a través de diversos procesos. Ayuda a proporcionar visibilidad en la canalización de analytics y simplifica errores de seguimiento a sus fuentes. También permite reproducir porciones específicas o entradas del flujo de datos para step-wise de depuración o regenerar la pérdida de producción. De hecho, los sistemas de bases de datos han utilizado dicha información, llamado origen de datos, para abordar retos depuración y validación similar ya.[2]
Procedencia de datos las entradas de los documentos, entidades, sistemas y procesos que influyen en la información de interés, en efecto, proporcionando un registro histórico de los datos y sus orígenes. La evidencia generada apoya actividades forenses esenciales tales como análisis de datos-dependencia, detección de error/compromiso y recuperación y análisis de auditoría y cumplimiento. "Linaje es un tipo simple de ¿por qué procedencia."[2]
Contenido
- 1 Caso de linaje de datos
- 1.1 Big Data de depuración
- 1.2 Desafíos en la depuración de datos grandes
- 1.2.1 Escala masiva
- 1.2.2 Datos no estructurados
- 1.2.3 Tiempo de pasada
- 1.2.4 Plataforma compleja
- 1.3 Solución propuesta
- 2 Procedencia de datos
- 3 Captura de linaje
- 4 Activos vs linaje perezoso
- 5 Actores
- 6 Asociaciones
- 7 Arquitectura
- 8 Flujo de datos de reconstrucción
- 8.1 Tablas de asociación
- 8.2 Asociación gráfica
- 8.2.1 Enlaces explícitamente especificado
- 8.2.2 Inferir lógicamente enlaces
- 8.2.3 Enlaces implícito a través del intercambio de datos
- 8.3 Ordenación topológica
- 9 Seguimiento y repetición
- 10 Desafíos
- 10.1 Escalabilidad
- 10.2 Tolerancia a fallos
- 10.3 Operadores de caja negra
- 10.4 Seguimiento eficiente
- 10.5 Repetición sofisticada
- 10.6 Detección de anomalías
- 11 Véase también
- 12 Referencias
Caso de linaje de datos
El mundo de la datos de grandes está cambiando dramáticamente ante nuestros ojos. Las estadísticas dicen que noventa por ciento (90%) de los datos de todo el mundo se ha creado en los últimos dos años solo. [3]. Esta explosión de datos ha dado como resultado el número creciente de sistemas y automatización en todos los niveles en todos los tamaños de las organizaciones.
Hoy en día, los sistemas distribuidos como Google Reducir el mapa[4], Microsoft dríade[5], Apache Hadoop [6](un proyecto de código abierto) y Google Pregel[7] ofrecen estas plataformas para empresas y usuarios. Sin embargo, incluso con estos sistemas, datos de grandes Análisis pueden tomar varias horas, días o semanas para ejecutar, simplemente debido a los volúmenes de datos involucrados. Por ejemplo, un algoritmo de predicción de calificaciones para el desafío de Netflix Premio tomó casi 20 horas para ejecutar 50 núcleos, y una tratamiento tarea para estimar la información geográfica a gran escala de la imagen tomó tres días para completar usando 400 núcleos[8]. "El gran telescopio sinóptico de encuesta se espera que genere terabytes de datos cada noche y eventualmente tienda más de 50 petabytes, mientras que en el sector de la bioinformática, la secuenciación del genoma 12 más grande casas en el mundo ahora tienda petabytes de datos para cada uno".[9] Debido al enorme tamaño de la datos de grandes, puede haber características de los datos que no están considerados en el algoritmo de aprendizaje máquina, posiblemente incluso afloramientos. Es muy difícil que un científico de datos para rastrear un desconocido o un resultado inesperado.
Big Data de depuración
Datos de grandes la analítica es el proceso de examen de grandes conjuntos de datos para descubrir patrones ocultos, desconocidas correlaciones, las tendencias del mercado, las preferencias del cliente y otra información útil para el negocio. Se aplican algoritmos de aprendizaje máquina etc. a los datos que transforman los datos. Debido al enorme tamaño de los datos, podría haber desconocido las características en los datos, posiblemente incluso afloramientos. Es bastante difícil para un científico de datos realmente depurar un resultado inesperado.
La gran escala y naturaleza no estructurada de datos, la complejidad de estos oleoductos analytics y largos tiempos de ejecución plantean significativa capacidad de administración y depuración de desafíos. Ni un solo error en estos análisis puede ser extremadamente difícil identificar y eliminar. Mientras que uno puede depurarlos por volver a ejecutar el análisis entero a través de un depurador para la depuración de step-wise, esto puede ser costoso debido a la cantidad de tiempo y los recursos necesarios. Validación de datos y auditoría son otros importantes problemas debido a la creciente facilidad de acceso a las fuentes de datos relevantes para su uso en experimentos, intercambio de datos entre las comunidades científicas y el uso de datos de terceros en las empresas [10][11][12][13].Estos problemas sólo serán más grandes y más agudo que estos sistemas y datos continúan creciendo. Por lo tanto, más costo-eficientes formas de analizar análisis del sistema de disco son cruciales para su uso continuo.
Desafíos en Big Data Depuración
Escala masiva
Las últimas dos décadas han visto una explosión nuclear en la recolección y almacenamiento de información digital. En 2012, 2.8 zettabytes— Eso es 1 sextillion bytes, o el equivalente de tweets 9223372.036854775807 trillones — fueron creadas o replicado, según la firma de investigación IDC. Hay cientos o miles de bases de datos de escala petabyte hoy en día, y comparamos su tamaño a lo que existió hace dos décadas, cada vez la base de comparación sería cero. Aquí le damos un vistazo a algunos de los conjuntos de datos más grandes e interesantes de todo el mundo. Trabajar con esta escala de datos se ha convertido en un reto [14].
Datos no estructurados
La frase datos no estructurados generalmente se refiere a la información que no reside en una base de datos tradicionales filas columnas. Como era de esperar, es lo contrario de datos estructurados los datos almacenados en los campos de una base de datos. Los archivos de datos no estructurados suelen incluyen texto y contenido multimedia. Los ejemplos incluyen mensajes de correo electrónico, documentos de procesamiento, vídeos, fotos, archivos de audio, presentaciones, páginas web y muchos otros tipos de documentos comerciales. Tenga en cuenta que aunque este tipo de archivos puede tener una estructura interna, todavía son considerados "no estructurados" porque los datos que contienen no encajan perfectamente en una base de datos. Los expertos estiman que 80 a 90 por ciento de los datos en cualquier organización es contenido no estructurado. Y la cantidad de datos no estructurados en empresas está creciendo más rápido de las bases de datos estructurados están creciendo significativamente a menudo muchas veces. "Datos de grandes puede incluir datos tanto estructurados como no estructurados, pero IDC estima que el 90 por ciento de datos de grandes es los datos no estructurados".[15]
Tiempo de pasada
En hiper competitivo ambiente de negocios actual, las empresas no sólo tienen que encontrar y analizar los datos pertinentes que necesitan, lo deben encontrar rápidamente. El desafío está pasando por los puro volúmenes de datos y acceder al nivel de detalle necesario, todo a una velocidad alta. El desafío sólo crece como el grado de granularidad aumenta. Una posible solución es hardware. Algunos proveedores utilizan memoria mayor y poderoso paralelo extremadamente rápido procesamiento de grandes volúmenes de crujido de datos. Otro método es poner datos en memoria pero usando una red informática de enfoque, donde muchas máquinas se utilizan para resolver un problema. Ambos enfoques permiten a las organizaciones explorar los volúmenes de datos enorme. Incluso esto este nivel de sofisticado hardware y software, algunas de las tareas en gran escala de procesamiento de imágenes tomarme unos días a semanas[16]. Depuración de la informática es extremadamente difícil debido a tiempos de largo plazo.
Plataforma compleja
Big Data las plataformas tienen una estructura muy complicada. Datos se distribuyen entre varias máquinas. Normalmente los puestos de trabajo se asignan a varias máquinas y posteriormente se combinaron los resultados por reducir las operaciones. Depuración de un datos de grandes tubería llega a ser muy difícil debido a la naturaleza misma del sistema. No será una tarea fácil para el científico de datos averiguar datos de la máquina que tienen los afloramientos y características desconocidas causando un algoritmo especial para dar resultados inesperados.
Solución propuesta
Procedencia de datos o linaje de datos puede utilizarse hacer la depuración de errores datos de grandes tubería más fácil. Esto requiere la recopilación de datos acerca de las transformaciones de datos. El debajo de sección explicará la procedencia de datos con más detalle.
Procedencia de datos
Procedencia de datos proporciona un registro histórico de los datos y sus orígenes. La procedencia de los datos que se generan por transformaciones complejas tales como flujos de trabajo es de un valor considerable para los científicos. De él, uno puede determinar la calidad de los datos en base a sus datos ancestrales y derivaciones, pista traseras fuentes de errores, permitir automatizado re-interpretación de derivaciones para actualizar datos y proporcionar atribución de fuentes de datos. Procedencia también es esencial para el dominio del negocio donde puede ser utilizado para perforar hasta la fuente de datos en un almacén de datos, seguimiento de la creación de propiedad intelectual y proporcionar una pista de auditoría para fines reglamentarios.
Se propone el uso de procedencia de datos en sistemas distribuidos para localizar registros a través de un flujo de datos, reproducir el flujo de datos en un subconjunto de sus entradas originales y depurar flujos de datos. Para ello, es necesario hacer un seguimiento de la serie de entradas a cada operador, que fueron utilizadas para derivar cada una de sus salidas. Aunque existen varias formas de procedencia, tales como copia-procedencia y cómo-procedencia [13], [17], la información que necesitamos es una forma simple de por eso-procedencia o linaje, tal como se define por Cui et al.[18].
Captura de linaje
Intuitivamente, para una producción de operador T salida o, linaje consta de trillizos de forma {I, T, o}, donde I es el conjunto de insumos a T utilizada para derivar o linaje de captura para cada operador T en un flujo de datos permite a los usuarios a hacer preguntas tales como "Qué salidas fueron producidos por una entrada que el operador T?" y "Qué insumos producción en operador T de salida o"?[2] Una consulta que encuentra las entradas de derivar una salida se llama una consulta de seguimiento hacia atrás, mientras que encuentra las salidas producidas por una entrada es una consulta de seguimiento hacia adelante[19]. Rastreo hacia atrás es útil para depurar, mientras traza hacia adelante es útil para el seguimiento de propagación de error.[19] Las consultas de seguimiento también forman la base para la reproducción de un flujo de datos original [18][11][19]. Sin embargo, para utilizar eficientemente linaje en un sistema de disco, tenemos que ser capaces de linaje en múltiples niveles (o resulta) de los operadores y los datos de captura, captura de linaje preciso para el procesamiento de disco construcciones y ser capaz de rastrear a través de múltiples etapas de flujo de datos eficientemente.
Sistema de disco consta de varios niveles de operadores y datos y casos de uso diferente del linaje pueden dictar el nivel en que linaje se debe ser capturado. Linaje puede ser capturado en el nivel del trabajo, la utilización de archivos y dando linaje tuplas de forma {IF i, disipa M, i}, linaje también puede ser capturado en el nivel de cada tarea, usando los registros y dar, por ejemplo, linaje tuplas de forma {(k rr, v rr), mapa, (k m, v m)}. La primera forma de linaje se llama linaje de grano grueso, mientras que la segunda forma se llama linaje de grano fino. Integración de linaje a través de diferente resulta permite a los usuarios a hacer preguntas tales como "Qué archivo leído por un trabajo de MapReduce producido este registro salida particular?" y puede ser útil en la depuración a través de diferente resulta operador y datos dentro de un flujo de datos.[2]

Para capturar el linaje-to-end en un sistema de disco, utilizamos el modelo Ibis [20], que introduce la noción de jerarquías de contención para los operadores y datos. Concretamente, Ibis propone que un operador puede ser contenido dentro de otra y se llama una relación entre dos operadores contención de operador. "Contención operador implica que el operador independiente (o niño) realiza una parte de la operación lógica del operador que contiene (o padres)".[2] Por ejemplo, una tarea de MapReduce está contenida en un trabajo. Relaciones de contención similares existen para datos, llamada contención datos. Contención de datos implica que los datos contenidos están un subconjunto de los datos que contiene (superconjunto).

Activos vs linaje perezoso
Colección de linaje perezoso típicamente captura sólo linaje de grano grueso en tiempo de ejecución. Estos sistemas de incurrir en gastos de captura baja debido a la poca cantidad de linaje que capturan. Sin embargo, para responder a las consultas de seguimiento de grano fino, deben repetir el flujo de datos en todo o gran parte de su entrada y recoger grano fino linaje durante la reproducción. Este enfoque es adecuado para sistemas forenses, donde un usuario quiere depurar una mala salida observada.
Sistemas de recolección activa de capturan todo linaje del flujo de datos en tiempo de ejecución. El tipo de linaje capturan puede ser de grano grueso o grano fino, pero no requieren ningún cómputos más en el flujo de datos después de su ejecución. Sistemas de recolección activa grano fino de linaje incurrir en mayores gastos de captura que los sistemas de colección lazy. Sin embargo, permiten sofisticada replay y depuración.[2]
Actores
Un actor es una entidad que transforma los datos; puede ser un vértice Dríada, individuales del mapa y reducir un trabajo de MapReduce, operadores o una tubería de flujo de datos entero. Actores actúan como cajas negras y las entradas y salidas del actor están intervenidas para capturar linaje en forma de asociaciones, donde una asociación es un triplete {i, T, o} que relaciona la entrada con una salida o para un actor T. La instrumentación así capta linaje en un actor de un flujo de datos a la vez, lo empalme en un conjunto de asociaciones para cada actor. El desarrollador del sistema necesita capturar los datos que actor Lee (de otros actores) y el que actor escribe (para otros actores). Por ejemplo, un desarrollador puede tratar el rastreador de Hadoop trabajo como actor al registrar el conjunto de ficheros leído y escrito por cada trabajo. [21]
Asociaciones
La asociación es una combinación de las entradas, salidas y la operación en sí. La operación se representa en términos de una caja negra también conocido como el actor. Las asociaciones de describen las transformaciones que se aplican a los datos. Las asociaciones se almacenan en las tablas de asociación. Cada actor único está representada por su propia tabla de asociación. Una asociación se parece a {i, T, o} donde i es el conjunto de entradas al actor T y o conjunto de salidas dado producido por el actor. Las asociaciones son las unidades básicas del linaje de datos. Asociaciones individuales son golpeadas más tarde juntos para construir toda la historia de las transformaciones que se aplicaron a los datos.[2]
Arquitectura
Datos de grandes sistemas de escalan horizontalmente i.e aumento capacidad por mediante la adición de nuevas entidades de hardware o software en el sistema distribuido. El sistema distribuido actúa como una única entidad en el nivel lógico aunque se compone de varias entidades de hardware y software. El sistema debe continuar manteniendo esta propiedad después de escala horizontal. Una ventaja importante de escalabilidad horizontal es que puede proporcionar la capacidad de aumentar la capacidad sobre la marcha. La ventaja más grande es que escala horizontal puede realizarse utilizando los herrajes de las materias primas.
La función de escalado horizontal de Big Data los sistemas deben tenerse en cuenta al crear la arquitectura de la tienda de linaje. Esto es esencial porque la tienda de linaje sí mismo también debe ser capaz de escala en paralelo con el Datos de grandes sistema. El número de asociaciones y la cantidad de almacenamiento de información requerido para almacenar linaje se incrementan con el aumento en el tamaño y la capacidad del sistema. La arquitectura de Datos de grandes sistemas hace el uso de un almacén único linaje no apropiado e imposible de escala. La solución inmediata a este problema es distribuir la tienda linaje propio.[2]
El mejor de los casos es recurrir a una tienda local de linaje para cada máquina en la red del sistema distribuido. Esto permite que la tienda de linaje también escalar horizontalmente. En este diseño, el linaje de las transformaciones de datos aplicado a los datos en una máquina en particular es almacenado en el almacén local de linaje de esa máquina específica. La tienda de linaje almacena típicamente tablas de asociación. Cada actor está representada por su propia tabla de asociación. Las filas son las asociaciones de ellos mismos y columnas representan entradas y salidas. Este diseño soluciona 2 problemas. Permite la escala horizontal de la tienda de linaje. Si se usó un almacén único linaje centralizada, entonces esta información tuvieron que ser llevados por la red, que causaría la latencia de red adicionales. La latencia de la red también es evitada por el uso de una tienda de linaje distribuidos.[21]
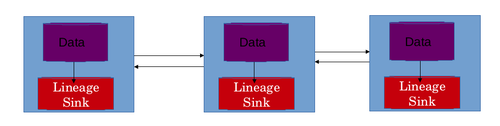
Flujo de datos de reconstrucción
La información almacenada en términos de asociaciones debe combinarse por algunos medios para obtener el flujo de datos de un trabajo en particular. En un sistema distribuido un trabajo se descompone en múltiples tareas. Una o más instancias de ejecutar una tarea particular. Los resultados producidos en estas máquinas individuales se combinan después para terminar el trabajo. Tareas que se ejecutan en diferentes máquinas realizan múltiples transformaciones en los datos en la máquina. Todas las transformaciones aplicadas a los datos en máquinas se almacena en la tienda local de linaje de que las máquinas. Esta información tiene que combinar para obtener el linaje de todo el trabajo. El linaje de todo el trabajo debería ayudar a entender el flujo de datos del trabajo científico de los datos y puede utilizar el flujo de datos para depurar el datos de grandes tubería. El flujo de datos es reconstruido en 3 etapas.
Tablas de asociación
La primera etapa de la reconstrucción del flujo de datos es el cómputo de las mesas de la asociación. Las tablas de asociación existe para cada actor en cada tienda local linaje. La mesa de toda asociación para un actor puede ser computada mediante la combinación de estas tablas de asociación individual. Esto se hace generalmente usando una serie de igualdad se une basado en los propios actores. En algunos escenarios las tablas pueden también unirá utilizando insumos como clave. Los índices también pueden utilizarse para mejorar la eficacia de una combinación.Las tablas se unió a necesitan ser almacenados en una sola instancia o una máquina para continuar seguir procesando. Existen múltiples esquemas que se utilizan para recoger una máquina donde una combinación podría ser computada. La más fácil que ser el uno con carga mínima de la CPU. Limitaciones de espacio también deben mantenerse en mente mientras recogía la instancia donde pasaría a unirse.
Asociación gráfica
El segundo paso en la reconstrucción del flujo de datos está computando un gráfico de Asociación de la información del linaje. El gráfico representa los pasos en el flujo de datos. Los actores actúan como los vértices y las asociaciones actúan como los bordes. Cada actor T está ligada a sus actores ascendentes y descendentes en el flujo de datos. Actor ascendente de T es uno que produjo la entrada de T, mientras que un actor descendente es aquel que consume la salida de T. Las relaciones de contención se consideran siempre al crear los vínculos. El gráfico se compone de tres tipos de enlaces o bordes.
Enlaces explícitamente especificado
El vínculo más simple es un enlace entre dos actores explícitamente especificado. Estos enlaces se especifican explícitamente en el código de un algoritmo de aprendizaje automático. Cuando un actor es consciente de su agente exacta río arriba o río abajo, puede comunicarse esta información al linaje API. Esta información es utilizada más adelante para vincular estos actores durante la consulta de seguimiento. Por ejemplo, en el MapReduce arquitectura, cada instancia mapa sabe el lector registro exacto ejemplo cuya producción consume.[2]
Inferir lógicamente enlaces
Los desarrolladores pueden adjuntar el flujo de datos arquetipos a cada actor lógica. Un arquetipo de flujo de datos explica cómo los tipos de niños de un tipo de actor se arreglan en un flujo de datos. Con la ayuda de esta información, se puede inferir un vínculo entre cada actor de un tipo de fuente y un tipo de destino. Por ejemplo, en el MapReduce arquitectura, el tipo de actor mapa es la fuente para reducir y viceversa. El sistema deduce esto de los arquetipos de flujo de datos y debidamente enlaces mapa instancias con reducir las instancias. Sin embargo, puede haber varios MapReduce reducen puestos de trabajo en el flujo de datos y vincular todas las instancias de mapa con todos los casos pueden crear enlaces falsos. Para evitar esto, estos vínculos están restringidos a instancias del actor contenidas dentro de una instancia común del actor de un tipo de actor que contiene (o padres). Por lo tanto, mapa y reducir las instancias se asocian únicamente con unos a otros si pertenecen al mismo trabajo.[2]
Enlaces implícito a través del intercambio de datos
En sistemas distribuidos, a veces hay enlaces implícito, que no se especifiquen durante la ejecución. Por ejemplo, un vínculo implícito existe entre un actor que le escribió a un archivo y otro actor que leí de él. Tales enlaces conectan actores que utilizan un conjunto de datos común para la ejecución. El conjunto de datos es la salida del primer actor y la entrada del actor siguiendo.[2]
Ordenación topológica
El paso final en la reconstrucción del flujo de datos es el Ordenación topológica de la gráfica de la asociación. El grafo dirigido creado en el paso anterior es topológicamente ordenado para obtener el orden en el que los actores han modificado los datos. Esta orden de heredar de los actores define el flujo de datos de la tubería de datos grande o tarea.
Seguimiento y repetición
Este es el paso más importante en Big Data depuración. El linaje capturado es combinado y procesado para obtener el flujo de datos de la tubería. El flujo de datos ayuda al científico de datos o un desarrollador para investigar profundamente los actores y sus transformaciones. Este paso permite al científico de datos para averiguar la parte del algoritmo que genera la salida inesperada. A datos de grandes tubería puede salir mal en 2 formas amplias. La primera es la presencia de un agente sospechoso en el flujo de datos. El segundo es la existencia de valores atípicos en los datos.
El primer caso puede ser depurado por rastrear el flujo de datos. Utilizando información de linaje y flujo de datos juntos un científico de datos puede averiguar cómo se convierten las entradas en salidas. Durante el proceso de actores que se comportan de forma inesperada pueden quedar atrapados. Estos actores pueden extraerse el flujo de datos o pueden ser aumentadas por nuevos actores para cambiar el flujo de datos. El flujo de datos mejorado puede reproducirse para probar la validez de ella. Depuración defectuosas actores incluyen recursivamente realizando grabaciones de grano grueso en actores en el flujo de datos [22], que puede ser costoso en recursos para formularios largos. Otro enfoque es inspeccionar manualmente los registros de linaje para encontrar anomalías [12][23], que puede ser tedioso y lento a través de varias etapas de un flujo de datos. Además, estos enfoques funcionan sólo cuando el científico de datos puede descubrir malas salidas. Para depurar analítica sin salida mal conocido, el científico de datos necesita analizar el flujo de datos para un comportamiento sospechoso en general. Sin embargo, a menudo, un usuario no puede saber el comportamiento normal y no puede especificar predicados. Esta sección describe una metodología para el análisis retrospectivo de linaje para identificar actores defectuosos en un flujo de datos multi-etapa depuración. Creemos que los cambios bruscos en la conducta de un actor, como su selectividad promedio, procesamiento de salida o tasa de tamaño, es característica de una anomalía. Linaje puede reflejar dichos cambios en el comportamiento del actor con el tiempo y a través de instancias diferentes actor. Por lo tanto, linaje de minería para identificar tales cambios puede ser útil en la depuración de los actores defectuosos en un flujo de datos.
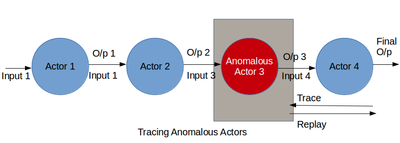
El segundo problema es decir la existencia de valores atípicos pueden identificarse también ejecutando el paso de flujo de datos sabio y mirando en las salidas transformadas. El científico de datos encuentra un subconjunto de salidas que no están de acuerdo con el resto de salidas. Las entradas que provocan estas malas salidas son los valores extremos en los datos. Este problema puede resolverse quitando el conjunto de valores extremos de los datos y reproducir todo el flujo de datos. También se puede resolver mediante la modificación de la máquina de aprendizaje algoritmo por agregar, quitar o actores moviéndose en el flujo de datos. Los cambios en el flujo de datos son exitosos si el flujo de datos reproducido no produce malas salidas.

Desafíos
Aunque uso datos linaje es una forma novedosa de depuración de datos de grandes las tuberías, el proceso no es sencillo. Los desafíos son escalabilidad de tienda de linaje, tolerancia a fallos de la tienda el linaje, precisa captura de linaje para operadores de caja negra y muchos otros. Estos desafíos deben considerarse cuidadosamente y las desventajas entre ellas deben evaluarse para hacer un diseño realista de linaje de datos de captura.
Escalabilidad
Los sistemas de discos son principalmente sistemas de procesamiento por lotes diseñados para alto rendimiento. Ejecutarán varios trabajos por analytics, con varias tareas por puesto de trabajo. El número total de operadores de ejecutar en cualquier momento en un clúster puede variar desde cientos a miles dependiendo del tamaño del clúster. Captura de linaje para estos sistemas debe ser capaz de escala a dos grandes volúmenes de datos y numerosos operadores para evitar un cuello de botella para el análisis del disco.
Tolerancia a fallos
Sistemas de captura de linaje también deben ser tolerantes para evitar volver a ejecutar los flujos de datos para capturar linaje. Al mismo tiempo, también deben acomodar fallas en el sistema de disco. Para ello, debe ser capaces de identificar una tarea fallida de disco y Evite guardar copias duplicadas de linaje entre el linaje parcial generado por la tarea fallida y linaje duplicado producida por la tarea reinicia. Un sistema de linaje también debe ser capaz de manejar con gracia múltiples instancias de sistemas locales de linaje bajando. Esto logra almacenando las réplicas de las asociaciones de linaje en varias máquinas. La réplica puede actuar como una copia de seguridad en el caso de la copia real se pierden.
Operadores de caja negra
Sistemas de linaje para formularios de disco deben ser capaces de capturar linaje precisa a través de los operadores de caja negra para habilitar la depuración de grano fino. Los enfoques actuales esto incluyen a Prober, que pretende encontrar el conjunto mínimo de insumos que pueden producir una salida especificada para un operador de caja negra por reproducir el flujo de datos varias veces para deducir el conjunto mínimo[24]y rebanar dinámica, según lo utilizado por Zhang et al.[25] linaje para capturar NoSQL operadores a través de reescritura binario para computar rebanadas dinámicos. Aunque produciendo linaje altamente preciso, tales técnicas pueden incurrir en gastos de tiempo significativo para la captura o seguimiento, y puede ser preferible al comercio en cambio algunos exactitud para un mejor rendimiento. Por lo tanto, hay una necesidad de un sistema de colección de linaje para formularios de disco que pueden capturar linaje de operadores arbitrarios con razonable precisión y sin gastos significativos en captura o seguimiento.
Seguimiento eficiente
Trazo es esencial para la depuración, durante el cual, un usuario puede emitir varias consultas de seguimiento. Por lo tanto, es importante que el trazado tiene plazos de entrega rápidos. Ikeda et al. [19]puede realizar consultas de seguimiento eficaz hacia atrás para formularios de MapReduce, pero no son genéricos a diferentes sistemas de discos y no haga eficientes reenviar consultas. Lápiz labial[26], un sistema de linaje de cerdo[27], mientras que es capaz de realizar seguimiento de adelante y atrás, es específico para los operadores de cerdo y SQL y sólo puede realizar seguimiento de grano grueso para operadores de caja negra. Por lo tanto, hay una necesidad de un sistema de linaje que permite remontar hacia adelante y hacia atrás eficiente para los sistemas de discos genéricos y formularios con operadores de caja negra.
Repetición sofisticada
Reproducción sólo entradas específicas o porciones de un flujo de datos es crucial para la depuración eficiente y simulando escenarios de qué pasaría si. Ikeda et al presentar una metodología para la actualización basada en el linaje, que selectivamente repite actualizados entradas para recalcular salidas afectadas[28]. Esto es útil durante la depuración para volver a calcular salidas cuando se ha fijado una mala entrada. Sin embargo, a veces un usuario puede querer quitar la mala entrada y reproducción del linaje de salidas previamente afectados por el error para producir salidas libres de error. Llamamos esta reproducción exclusiva. Otro uso de la repetición en la depuración consiste en reproducir malas entradas para depuración paso a paso (llamado repetición selectiva). Los enfoques actuales al uso de linaje en los sistemas de discos no abordan estos. Por lo tanto, hay una necesidad de un sistema de linaje que puede realizar las repeticiones tanto exclusivas y selectivas atender diversas necesidades de depuración.
Detección de anomalías
Una de las principales preocupaciones de depuración en los sistemas de discos es identificar los operadores defectuosos. En formularios largos con varios centenares de operadores o tareas, inspección manual puede ser tedioso y prohibitivo. Aunque linaje se utiliza para restringir el subconjunto de los operadores para examinar, el linaje de una sola salida todavía puede abarcar varios operadores. Hay una necesidad de un barato sistema automatizado de depuración, que puede restringir sustancialmente el conjunto de operadores potencialmente defectuosos, con razonable precisión, para minimizar la cantidad de examen manual necesaria.[2]
Véase también
- Procedencia
- Big Data
- Ordenación topológica
- Depuración
- NoSQL
- Escalabilidad
- Grafo dirigido acíclico
Referencias
- ^ https://www.techopedia.com/Definition/28040/Data-Lineage
- ^ a b c d e f g h i j k l Jeux, Soumyarupa. (2012). newt: una arquitectura para el linaje basado en replay y depuración en los sistemas de discos. UC San Diego: b7355202. Obtenido de: https://escholarship.org/UC/Item/3170p7zn
- ^ https://newstex.com/2014/07/12/thedataexplosionin2014minutebyminuteinfographic/
- ^ Jeffrey Dean y Sanjay Ghemawat. MapReduce: procesamiento de datos simplificada en grandes grupos. Commun. ACM, 1:107-113, enero de 2008.
- ^ Michael Isard, Mihai Budiu, Yu Yuan, Andrew Birrell y Dennis Fetterly. Dríade: distribuye programas de datos paralela de bloques secuenciales. En las actas de la 2ª Conferencia Europea de ACM SIGOPS/EuroSys onComputer sistemas 2007, EuroSys ' 07, páginas 59-72, Nueva York, NY, USA, 2007. ACM.
- ^ Apache Hadoop. https://Hadoop.apache.org.
- ^ Grzegorz Malewicz, Matthew H. Austern, Aart J.C Bik, James C. Dehnert, cuerno de Ilan, Naty Leiser y Grzegorz Czajkowski. PreGel: un sistema de procesamiento gráfico de gran escala. En Proceedings of the 2010 Conferencia Internacional sobre gestión de datos, SIGMOD 10, páginas 135-146, Nueva York, NY, USA, 2010. ACM.
- ^ Shimin Chen y Steven W. Schlosser. -Reducir el mapa cumple con variedades más amplias de aplicaciones. Informe técnico, investigación de Intel, 2008.
- ^ El diluvio de datos en la genómica. https://www-304.IBM.com/Connections/blogs/ibmhealthcare/entry/Data sobrecarga en genomics3? lang = de, 2010.
- ^ Yogesh L. Simmhan, Beth Plale y Dennis Gannon. Una encuesta de datos probar-nance en e-ciencia. SIGMOD REC, 3:31 – 36, septiembre de 2005.
- ^ a b Ian Foster, Jens Vockler, Michael Wilde y Yong Zhao. Quimera: Un sistema de datos Virtual para representar, consultas y automatización de datos derivación. En la XIV Conferencia Internacional sobre gestión de base de datos científicos y estadísticos, de julio de 2002.
- ^ a b Benjamin H. Sigelman, Luiz André Barroso, Mike Burrows, Pat Stephenson, Manoj Plakal, Donald Beaver, Saul Jaspan y Chandan Shanbhag. Dapper, a gran escala distribuye sistemas de rastreo de infraestructura. Informe técnico, Google Inc, 2010.
- ^ a b Peter Buneman, Sanjeev Khanna y Wang Chiew bronceado. Procedencia de datos: algunas cuestiones básicas. En los procedimientos de la XX Conferencia sobre bases de SoftwareTechnology y Theoretical Computer Science, FST TCS 2000, páginas 87 – 93, Londres, UK, UK, 2000. Springer-Verlag
- ^ Atado con alambre. https://www.Wired.com/2013/04/BigData/
- ^ Webopedia https://www.webopedia.com/term/U/unstructured_data.html
- ^ SAS. https://www.SAS.com/resources/Asset/Five-Big-Data-Challenges-article.pdf
- ^ Robert Ikeda y Jennifer Widom. Linaje de datos: una encuesta. Informe técnico, Stanford University, 2009.
- ^ a b Cui Y. y J. Widom. Seguimiento de linaje para datos generales del almacén transformaciones. Diario de VLDB, 12.1, 2003.
- ^ a b c d Robert Ikeda, Hyunjung Park y Jennifer Widom. Procedencia para generalizado mapa y reducir los flujos de trabajo. En Proc. de CIDR, enero de 2011.
- ^ C. Olston y a. Das Sarma. Hotel ibis: Una procedencia manager para sistemas multicapas. En Proc. de CIDR, enero de 2011.
- ^ a b Dionysios Logothetis, De Soumyarupa y Kenneth Yocum. 2013. captura de linaje escalable para la depuración de análisis de disco. En las actas del IV Simposio Anual sobre Cloud Computing (SOCC 13). ACM, Nueva York, NY, Estados Unidos, artículo 17, 15 páginas.
- ^ Wenchao Zhou, Qiong Fei, Arjun Narayan, Andreas Haeberlen, Loo Boon Thau y Micah Sherr. Procedencia de red segura. En Proceedings of 23 ACM Symposium on funcionamiento sistema principios (SOSP), diciembre de 2011.
- ^ Rodrigo Fonseca, George Porter, Randy H. Katz, Scott Shenker y Ion Stoica. X-trace: Un red omnipresente trazo marco. En las actas de Inde ' 07, 2007.
- ^ Anish Das Sarma, Alpa Jain y Philip Bohannon. PROBER: Ad-Hoc depuración de extracción y las tuberías de integración. Informe técnico, Yahoo, abril de 2010.
- ^ Mingwu Zhang, Xiangyu Zhang, Xiang Zhang y Sunil Prabhakar. Rastreo de linaje más allá de los operadores relacionales. En Proc. Conferencia sobre Bases de datos muy grandes (VLDB), septiembre de 2007.
- ^ Yael Amsterdamer, Susan B. Davidson, Daniel Deutch, Tova Milo y Julia Stoyanovich. Poner lápiz labial a un cerdo: procedencia de flujo de trabajo de base de datos estilo propicio. En Proc. de VLDB, agosto de 2011.
- ^ Christopher Olston, Benjamin Reed, Utkarsh Srivastava, Ravi Kumar y Andrew Tomkins. Jerigonza: no-tan-idioma para el procesamiento de datos. En Proc. de ACM SIGMOD, Vancouver, Canadá, junio de 2008.
- ^ Robert Ikeda, Semih Salihoglu y Jennifer Widom. Actualizar base de procedencia en los flujos de trabajo orientada a datos. En las actas de la XX Conferencia Internacional ACM sobre información y gestión del conocimiento, CIKM 11, páginas 1659 – 1668, Nueva York, NY, USA, 2011. ACM.